Wie man Suricata IDS zusammen mit Elastic Stack unter Debian 12 installiert und konfiguriert
Suricata ist ein Netzwerküberwachungsprogramm, das jedes Paket des Internetverkehrs, das durch deinen Server fließt, untersucht und verarbeitet. Es kann Ereignisse protokollieren, Warnungen auslösen und den Datenverkehr unterbrechen, wenn es verdächtige Aktivitäten entdeckt.
Du kannst Suricata entweder auf einem einzelnen Rechner installieren, um dessen Datenverkehr zu überwachen, oder es auf einem Gateway-Host einsetzen, um den gesamten ein- und ausgehenden Datenverkehr von anderen Servern, die mit ihm verbunden sind, zu überprüfen. Du kannst Suricata mit Elasticsearch, Kibana und Filebeat kombinieren, um ein Security Information and Event Management (SIEM) Tool zu erstellen.
In diesem Tutorial wirst du Suricata IDS zusammen mit ElasticStack auf einem Debian 12 Server installieren. Die verschiedenen Komponenten des Stacks sind:
- Elasticsearch zum Speichern, Indizieren, Korrelieren und Durchsuchen der Sicherheitsereignisse auf dem Server.
- Kibana, um die in Elasticsearch gespeicherten Logs anzuzeigen.
- Filebeat, um Suricatas
eve.jsonLogdatei zu analysieren und jedes Ereignis zur Verarbeitung an Elasticsearch zu senden. - Suricata, um den Netzwerkverkehr nach verdächtigen Ereignissen zu durchsuchen und die ungültigen Pakete zu verwerfen.
Das Tutorial ist in zwei Teile gegliedert: Im ersten Teil geht es um die Installation und Konfiguration von Suricata, im zweiten Teil um die Installation und Konfiguration von Elastic Stack.
Für unser Tutorial werden wir Suricata und den Elastic Stack auf verschiedenen Servern installieren.
Voraussetzungen
- Die Server, die den Elastic Stack und Suricata hosten, sollten mindestens 4 GB RAM und 2 CPU-Kerne haben.
- Die Server sollten in der Lage sein, über private IP-Adressen miteinander zu kommunizieren.
- Auf den Servern sollte Debian 12 mit einem nicht-root sudo Benutzer laufen.
- Wenn du von überall auf die Kibana-Dashboards zugreifen willst, richte eine Domain (
kibana.example.com) ein, die auf den Server zeigt, auf dem Elasticsearch installiert wird. - Installiere die wichtigsten Pakete auf beiden Servern. Einige von ihnen sind vielleicht schon installiert.
$ sudo apt install wget curl nano ufw software-properties-common dirmngr apt-transport-https gnupg2 ca-certificates lsb-release debian-archive-keyring unzip -y
- Vergewissere dich, dass auf beiden Servern alles auf dem neuesten Stand ist.
$ sudo apt update
TEIL 1
Schritt 1 – Suricata installieren
Suricata ist in den offiziellen Debian-Repositorien verfügbar. Installiere es mit dem folgenden Befehl.
$ sudo apt install suricata
Der Suricata-Dienst wird automatisch aktiviert und gestartet. Bevor du fortfährst, stoppe den Suricata-Dienst, da wir ihn zuerst konfigurieren müssen.
$ sudo systemctl stop suricata
Schritt 2 – Suricata konfigurieren
Suricata speichert seine Konfiguration in der Datei /etc/suricata/suricata.yaml. Der Standardmodus für Suricata ist der IDS (Intrusion Detection System) Modus, in dem der Datenverkehr nur protokolliert und nicht gestoppt wird. Wenn du neu in Suricata bist, solltest du den Modus unverändert lassen. Sobald du ihn konfiguriert und mehr gelernt hast, kannst du den IPS (Intrusion Prevention System) Modus einschalten.
Community ID einschalten
Das Feld Community ID erleichtert die Korrelation von Daten zwischen Datensätzen, die von verschiedenen Überwachungstools erstellt wurden. Da wir Suricata mit Elasticsearch verwenden werden, kann es nützlich sein, die Community ID zu aktivieren.
Öffne die Datei /etc/suricata/suricata.yaml zum Bearbeiten.
$ sudo nano /etc/suricata/suricata.yaml
Finde die Zeile # Community Flow ID und setze den Wert der Variable community-id auf true.
. . .
# Community Flow ID
# Adds a 'community_id' field to EVE records. These are meant to give
# records a predictable flow ID that can be used to match records to
# output of other tools such as Zeek (Bro).
#
# Takes a 'seed' that needs to be same across sensors and tools
# to make the id less predictable.
# enable/disable the community id feature.
community-id: true
. . .
Speichere die Datei, indem du Strg + X drückst und Y eingibst, wenn du dazu aufgefordert wirst.
Jetzt tragen deine Ereignisse eine ID wie 1:S+3BA2UmrHK0Pk+u3XH78GAFTtQ=, die du verwenden kannst, um Datensätze zwischen verschiedenen Monitoring-Tools abzugleichen.
Netzwerkschnittstelle auswählen
Die Standardkonfigurationsdatei von Suricata untersucht den Datenverkehr auf dem eth0 Gerät/der Netzwerkschnittstelle. Wenn dein Server eine andere Netzwerkschnittstelle verwendet, musst du diese in der Konfiguration aktualisieren.
Überprüfe den Gerätenamen deiner Netzwerkschnittstelle mit dem folgenden Befehl.
$ ip -p -j route show default
Du wirst eine Ausgabe wie die folgende erhalten.
[ {
"dst": "default",
"gateway": "159.223.208.1",
"dev": "eth0",
"protocol": "static",
"flags": [ ]
} ]
Die Variable dev bezieht sich auf das Netzwerkgerät. In unserer Ausgabe wird eth0 als Netzwerkgerät angezeigt. Je nach System kann deine Ausgabe anders aussehen.
Da du nun den Gerätenamen kennst, öffne die Konfigurationsdatei.
$ sudo nano /etc/suricata/suricata.yaml
Suche die Zeile af-packet: um die Zeilennummer 580 herum. Setze darunter den Wert der Variable interface auf den Gerätenamen deines Systems.
# Linux high speed capture support
af-packet:
- interface: eth0
# Number of receive threads. "auto" uses the number of cores
#threads: auto
# Default clusterid. AF_PACKET will load balance packets based on flow.
cluster-id: 99
. . .
Wenn du weitere Schnittstellen hinzufügen möchtest, kannst du dies am Ende des Abschnitts af-packet um die Zeile 650 herum tun.
Um eine neue Schnittstelle hinzuzufügen, füge sie direkt über dem Abschnitt - interface: default ein, wie unten gezeigt.
# For eBPF and XDP setup including bypass, filter and load balancing, please
# see doc/userguide/capture-hardware/ebpf-xdp.rst for more info.
- interface: enp0s1
cluster-id: 98
...
- interface: default
#threads: auto
#use-mmap: no
#tpacket-v3: yes
In unserem Beispiel haben wir eine neue Schnittstelle enp0s1 und einen eindeutigen Wert für die Variable cluster-id hinzugefügt. Bei jeder Schnittstelle, die du hinzufügst, musst du eine eindeutige Cluster-ID angeben.
Suche die Zeile pcap: und setze den Wert der Variable interface auf den Gerätenamen deines Systems.
# Cross platform libpcap capture support
pcap:
- interface: eth0
# On Linux, pcap will try to use mmap'ed capture and will use "buffer-size"
# as total memory used by the ring. So set this to something bigger
# than 1% of your bandwidth.
Um eine neue Schnittstelle hinzuzufügen, fügst du sie wie unten gezeigt direkt über dem Abschnitt - interface: default ein.
- interface: enp0s1
# Put default values here
- interface: default
#checksum-checks: auto
Wenn du fertig bist, speichere die Datei, indem du Strg + X drückst und Y eingibst, wenn du dazu aufgefordert wirst.
Schritt 3 – Suricata-Regeln konfigurieren
Suricata verwendet standardmäßig nur einen begrenzten Satz von Regeln, um Netzwerkverkehr zu erkennen. Mit einem Tool namens suricata-update kannst du weitere Regelsätze von externen Anbietern hinzufügen. Führe den folgenden Befehl aus, um zusätzliche Regeln hinzuzufügen.
$ sudo suricata-update -o /etc/suricata/rules 4/10/2023 -- 14:12:05 - <Info> -- Using data-directory /var/lib/suricata. 4/10/2023 -- 14:12:05 - <Info> -- Using Suricata configuration /etc/suricata/suricata.yaml 4/10/2023 -- 14:12:05 - <Info> -- Using /etc/suricata/rules for Suricata provided rules. ..... 4/10/2023 -- 14:12:05 - <Info> -- No sources configured, will use Emerging Threats Open 4/10/2023 -- 14:12:05 - <Info> -- Fetching https://rules.emergingthreats.net/open/suricata-6.0.10/emerging.rules.tar.gz. 100% - 4073339/4073339 ..... 4/10/2023 -- 14:12:09 - <Info> -- Writing rules to /etc/suricata/rules/suricata.rules: total: 45058; enabled: 35175; added: 45058; removed 0; modified: 0 4/10/2023 -- 14:12:10 - <Info> -- Writing /etc/suricata/rules/classification.config 4/10/2023 -- 14:12:10 - <Info> -- Testing with suricata -T. 4/10/2023 -- 14:12:33 - <Info> -- Done.
Der Teil -o /etc/suricata/rules des Befehls weist das Update-Tool an, die Regeln im Verzeichnis /etc/suricata/rules zu speichern. Dieser Parameter ist wichtig, da du sonst bei der Validierung die folgende Fehlermeldung erhältst.
<Warning> - [ERRCODE: SC_ERR_NO_RULES(42)] - No rule files match the pattern /etc/suricata/rules/suricata.rules
Regelsatzanbieter hinzufügen
Du kannst die Regeln von Suricata erweitern, indem du weitere Anbieter hinzufügst. Suricata kann Regeln von einer Vielzahl von kostenlosen und kommerziellen Anbietern beziehen.
Du kannst die Liste der Standardanbieter mit dem folgenden Befehl auflisten.
$ sudo suricata-update list-sources
Wenn du zum Beispiel den Regelsatz tgreen/hunting einbeziehen möchtest, kannst du ihn mit dem folgenden Befehl aktivieren.
$ sudo suricata-update enable-source tgreen/hunting 4/10/2023 -- 14:24:26 - <Info> -- Using data-directory /var/lib/suricata. 4/10/2023 -- 14:24:26 - <Info> -- Using Suricata configuration /etc/suricata/suricata.yaml 4/10/2023 -- 14:24:26 - <Info> -- Using /etc/suricata/rules for Suricata provided rules. 4/10/2023 -- 14:24:26 - <Info> -- Found Suricata version 6.0.10 at /usr/bin/suricata. 4/10/2023 -- 14:24:26 - <Info> -- Creating directory /var/lib/suricata/update/sources 4/10/2023 -- 14:24:26 - <Info> -- Enabling default source et/open 4/10/2023 -- 14:24:26 - <Info> -- Source tgreen/hunting enabled
Führe den Befehl suricata-update erneut aus, um die neuen Regeln herunterzuladen und zu aktualisieren. Suricata kann standardmäßig alle Regeländerungen verarbeiten, ohne neu zu starten.
Schritt 4 – Validierung der Suricata-Konfiguration
Suricata wird mit einem Validierungstool geliefert, das die Konfigurationsdatei und die Regeln auf Fehler überprüft. Führe den folgenden Befehl aus, um das Validierungstool zu starten.
$ sudo suricata -T -c /etc/suricata/suricata.yaml -v 4/10/2023 -- 14:24:43 - <Info> - Running suricata under test mode 4/10/2023 -- 14:24:43 - <Notice> - This is Suricata version 6.0.10 RELEASE running in SYSTEM mode 4/10/2023 -- 14:24:43 - <Info> - CPUs/cores online: 2 4/10/2023 -- 14:24:43 - <Info> - fast output device (regular) initialized: fast.log 4/10/2023 -- 14:24:43 - <Info> - eve-log output device (regular) initialized: eve.json 4/10/2023 -- 14:24:43 - <Info> - stats output device (regular) initialized: stats.log 4/10/2023 -- 14:24:53 - <Info> - 1 rule files processed. 35175 rules successfully loaded, 0 rules failed 4/10/2023 -- 14:24:53 - <Info> - Threshold config parsed: 0 rule(s) found 4/10/2023 -- 14:24:54 - <Info> - 35178 signatures processed. 1255 are IP-only rules, 5282 are inspecting packet payload, 28436 inspect application layer, 108 are decoder event only 4/10/2023 -- 14:25:07 - <Notice> - Configuration provided was successfully loaded. Exiting. 4/10/2023 -- 14:25:07 - <Info> - cleaning up signature grouping structure... complete
Das Flag -T weist Suricata an, im Testmodus zu laufen, das Flag -c konfiguriert den Speicherort der Konfigurationsdatei und das Flag -v gibt die ausführliche Ausgabe des Befehls aus. Je nach Systemkonfiguration und der Anzahl der hinzugefügten Regeln kann die Ausführung des Befehls einige Minuten dauern.
Schritt 5 – Suricata ausführen
Jetzt, wo Suricata konfiguriert und eingerichtet ist, ist es an der Zeit, die Anwendung zu starten.
$ sudo systemctl start suricata
Überprüfe den Status des Prozesses.
$ sudo systemctl status suricata
Wenn alles richtig funktioniert, solltest du die folgende Ausgabe sehen.
? suricata.service - Suricata IDS/IDP daemon
Loaded: loaded (/lib/systemd/system/suricata.service; enabled; preset: enabled)
Active: active (running) since Wed 2023-10-04 14:25:49 UTC; 6s ago
Docs: man:suricata(8)
man:suricatasc(8)
https://suricata-ids.org/docs/
Process: 1283 ExecStart=/usr/bin/suricata -D --af-packet -c /etc/suricata/suricata.yaml --pidfile /run/suricata.pid (code=exited, status=0/SUCCESS)
Main PID: 1284 (Suricata-Main)
Tasks: 1 (limit: 4652)
Memory: 211.7M
CPU: 6.132s
CGroup: /system.slice/suricata.service
??1284 /usr/bin/suricata -D --af-packet -c /etc/suricata/suricata.yaml --pidfile /run/suricata.pid
Oct 04 14:25:49 suricata systemd[1]: Starting suricata.service - Suricata IDS/IDP daemon...
Oct 04 14:25:49 suricata suricata[1283]: 4/10/2023 -- 14:25:49 - <Notice> - This is Suricata version 6.0.10 RELEASE running in SYSTEM mode
Oct 04 14:25:49 suricata systemd[1]: Started suricata.service - Suricata IDS/IDP daemon.
Es kann ein paar Minuten dauern, bis der Prozess alle Regeln analysiert hat. Daher ist die obige Statusüberprüfung kein vollständiger Hinweis darauf, ob Suricata läuft und bereit ist. Du kannst die Logdatei mit dem folgenden Befehl überwachen.
$ sudo tail -f /var/log/suricata/suricata.log
Wenn du die folgende Zeile in der Protokolldatei siehst, bedeutet das, dass Suricata läuft und bereit ist, den Netzwerkverkehr zu überwachen. Beende den Befehl tail, indem du die Tasten CTRL+C drückst.
4/10/2023 -- 14:26:12 - <Info> - All AFP capture threads are running.
Schritt 6 – Testen der Suricata-Regeln
Wir werden überprüfen, ob Suricata verdächtigen Datenverkehr erkennt. Der Suricata-Leitfaden empfiehlt, die ET-Open-Regel Nummer 2100498 mit dem folgenden Befehl zu testen.
$ curl http://testmynids.org/uid/index.html
Du wirst die folgende Antwort erhalten.
uid=0(root) gid=0(root) groups=0(root)
Der obige Befehl gibt vor, die Ausgabe des id Befehls zurückzugeben, der auf einem kompromittierten System ausgeführt werden kann. Um zu prüfen, ob Suricata den Datenverkehr erkannt hat, musst du die Protokolldatei mit der angegebenen Regelnummer überprüfen.
$ grep 2100498 /var/log/suricata/fast.log
Wenn deine Anfrage IPv6 verwendet hat, solltest du die folgende Ausgabe sehen.
10/04/2023-14:26:37.511168 [**] [1:2100498:7] GPL ATTACK_RESPONSE id check returned root [**] [Classification: Potentially Bad Traffic] [Priority: 2] {TCP} 2600:9000:23d0:a200:0018:30b3:e400:93a1:80 -> 2a03:b0c0:0002:00d0:0000:0000:0e1f:c001:53568
Wenn deine Anfrage IPv4 verwendet hat, würdest du die folgende Ausgabe sehen.
10/04/2023-14:26:37.511168 [**] [1:2100498:7] GPL ATTACK_RESPONSE id check returned root [**] [Classification: Potentially Bad Traffic] [Priority: 2] {TCP} 108.158.221.5:80 -> 95.179.185.42:36364
Suricata protokolliert Ereignisse auch in der Datei /var/log/suricata/eve.log im JSON-Format. Um diese Regeln lesen und interpretieren zu können, musst du jq installieren, was aber nicht Gegenstand dieses Lehrgangs ist.
TEIL 2
Wir sind fertig mit Teil eins des Tutorials, in dem wir Suricata installiert und getestet haben. Im nächsten Teil geht es darum, den ELK-Stack zu installieren und ihn so einzurichten, dass er Suricata und seine Logs visualisieren kann. Der zweite Teil des Tutorials sollte auf dem zweiten Server durchgeführt werden, sofern nicht anders angegeben.
Schritt 7 – Elasticsearch installieren
Der erste Schritt bei der Installation von Elasticsearch ist das Hinzufügen des Elastic GPG-Schlüssels zu deinem Server.
$ wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo gpg --dearmor -o /usr/share/keyrings/elasticsearch-keyring.gpg
Erstelle ein Repository für das Elasticsearch-Paket, indem du die Datei /etc/apt/sources.list.d/elastic-7.x.list erstellst.
$ echo "deb [signed-by=/usr/share/keyrings/elasticsearch-keyring.gpg] https://artifacts.elastic.co/packages/8.x/apt stable main" | sudo tee /etc/apt/sources.list.d/elastic-8.x.list
Aktualisiere die Repository-Liste deines Systems.
$ sudo apt update
Installiere Elasticsearch und Kibana.
$ sudo apt install elasticsearch
Du erhältst die folgende Ausgabe über die Installation von Elasticsearch.
--------------------------- Security autoconfiguration information ------------------------------ Authentication and authorization are enabled. TLS for the transport and HTTP layers is enabled and configured. The generated password for the elastic built-in superuser is : IuRTjJr+=NqIClxZwKBn If this node should join an existing cluster, you can reconfigure this with '/usr/share/elasticsearch/bin/elasticsearch-reconfigure-node --enrollment-token <token-here>' after creating an enrollment token on your existing cluster. You can complete the following actions at any time: Reset the password of the elastic built-in superuser with '/usr/share/elasticsearch/bin/elasticsearch-reset-password -u elastic'. Generate an enrollment token for Kibana instances with '/usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s kibana'. Generate an enrollment token for Elasticsearch nodes with '/usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s node'. -------------------------------------------------------------------------------------------------
Wir werden diese Informationen später verwenden.
Finde die private IP-Adresse deines Servers mit folgendem Befehl heraus.
$ ip -brief address show lo UNKNOWN 127.0.0.1/8 ::1/128 eth0 UP 159.223.220.228/20 10.18.0.5/16 2a03:b0c0:2:d0::e0e:c001/64 fe80::841e:feff:fee4:e653/64 eth1 UP 10.133.0.2/16 fe80::d865:d5ff:fe29:b50f/64
Notiere dir die private IP deines Servers (in diesem Fall10.133.0.2 ). Wir werden sie als your_private_IP bezeichnen. Die öffentliche IP-Adresse des Servers (159.223.220.228) wird im weiteren Verlauf des Lehrgangs als your_public_IP bezeichnet. Notiere dir auch den Namen der Netzwerkschnittstelle deines Servers: eth1.
Schritt 8 – Elasticsearch konfigurieren
Elasticsearch speichert seine Konfiguration in der Datei /etc/elasticsearch/elasticsearch.yml. Öffne die Datei zum Bearbeiten.
$ sudo nano /etc/elasticsearch/elasticsearch.yml
Elasticsearch akzeptiert standardmäßig nur lokale Verbindungen. Wir müssen dies ändern, damit Kibana über die private IP-Adresse darauf zugreifen kann.
Suche die Zeile #network.host: 192.168.0.1 und füge die folgende Zeile direkt darunter ein, wie unten gezeigt.
# By default Elasticsearch is only accessible on localhost. Set a different # address here to expose this node on the network: # #network.host: 192.168.0.1 network.bind_host: ["127.0.0.1", "your_private_IP"] # # By default Elasticsearch listens for HTTP traffic on the first free port it # finds starting at 9200. Set a specific HTTP port here:
Damit wird sichergestellt, dass Elastic weiterhin lokale Verbindungen akzeptiert, während Kibana über die private IP-Adresse erreichbar ist.
Im nächsten Schritt musst du einige Sicherheitsfunktionen aktivieren und sicherstellen, dass Elastic so konfiguriert ist, dass es nur auf einem einzigen Knoten läuft. Wenn du mehrere Elastic-Suchknoten verwenden willst, überspringst du die beiden folgenden Änderungen und speicherst die Datei.
Dazu fügst du die folgende Zeile am Ende der Datei ein.
. . . discovery.type: single-node
Außerdem kommentierst du die folgende Zeile aus, indem du ihr eine Raute (#) voranstellst.
#cluster.initial_master_nodes: ["kibana"]
Wenn du fertig bist, speichere die Datei, indem du Strg + X drückst und Y eingibst, wenn du dazu aufgefordert wirst.
Firewall konfigurieren
Füge die richtigen Firewall-Regeln für Elasticsearch hinzu, damit es über das private Netzwerk erreichbar ist.
$ sudo ufw allow in on eth1 $ sudo ufw allow out on eth1
Achte darauf, dass du im ersten Befehl den Namen der Schnittstelle auswählst, wie du ihn in Schritt 7 erhalten hast.
Starte Elasticsearch
Lade den Service Daemon neu.
$ sudo systemctl daemon-reload
Aktiviere den Elasticsearch-Dienst.
$ sudo systemctl enable elasticsearch
Jetzt, wo du Elasticsearch konfiguriert hast, ist es an der Zeit, den Dienst zu starten.
$ sudo systemctl start elasticsearch
Überprüfe den Status des Dienstes.
$ sudo systemctl status elasticsearch
? elasticsearch.service - Elasticsearch
Loaded: loaded (/lib/systemd/system/elasticsearch.service; enabled; preset: enabled)
Active: active (running) since Wed 2023-10-04 14:30:55 UTC; 8s ago
Docs: https://www.elastic.co
Main PID: 1731 (java)
Tasks: 71 (limit: 4652)
Memory: 2.3G
CPU: 44.355s
CGroup: /system.slice/elasticsearch.service
Elasticsearch-Passwörter erstellen
Nachdem du die Sicherheitseinstellungen von Elasticsearch aktiviert hast, musst du im nächsten Schritt das Passwort für den Superuser von Elasticsearch erstellen. Das Standardpasswort wurde bei der Installation angegeben und kann verwendet werden, aber es wird empfohlen, es zu ändern.
Führe den folgenden Befehl aus, um das Elasticsearch-Passwort zurückzusetzen. Wähle ein sicheres Passwort.
$ sudo /usr/share/elasticsearch/bin/elasticsearch-reset-password -u elastic -i This tool will reset the password of the [elastic] user. You will be prompted to enter the password. Please confirm that you would like to continue [y/N]y Enter password for [elastic]: <ENTER-PASSWORD> Re-enter password for [elastic]: <CONFIRM-PASSWORD> Password for the [elastic] user successfully reset.
Testen wir nun, ob Elasticsearch auf Abfragen antwortet.
$ sudo curl --cacert /etc/elasticsearch/certs/http_ca.crt -u elastic https://localhost:9200
Enter host password for user 'elastic':
{
"name" : "kibana",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "KGYx4poLSxKhPyOlYrMq1g",
"version" : {
"number" : "8.10.2",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "6d20dd8ce62365be9b1aca96427de4622e970e9e",
"build_date" : "2023-09-19T08:16:24.564900370Z",
"build_snapshot" : false,
"lucene_version" : "9.7.0",
"minimum_wire_compatibility_version" : "7.17.0",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "You Know, for Search"
}
Dies bestätigt, dass Elasticsearch voll funktionsfähig ist und reibungslos läuft.
Schritt 9 – Kibana installieren und konfigurieren
Installiere Kibana.
$ sudo apt install kibana
Der erste Schritt bei der Konfiguration von Kibana besteht darin, die Sicherheitsfunktion xpack zu aktivieren, indem du geheime Schlüssel generierst. Kibana verwendet diese geheimen Schlüssel, um Daten in Elasticsearch zu speichern. Das Dienstprogramm zur Erzeugung von geheimen Schlüsseln ist im Verzeichnis /usr/share/kibana/bin zu finden.
$ sudo /usr/share/kibana/bin/kibana-encryption-keys generate -q --force
Das Flag -q unterdrückt die Befehlsanweisungen, und das Flag --force sorgt dafür, dass neue Geheimnisse erzeugt werden. Du erhältst eine Ausgabe wie die folgende.
xpack.encryptedSavedObjects.encryptionKey: 248eb61d444215a6e710f6d1d53cd803 xpack.reporting.encryptionKey: aecd17bf4f82953739a9e2a9fcad1891 xpack.security.encryptionKey: 2d733ae5f8ed5f15efd75c6d08373f36
Kopiere die Ausgabe. Öffne die Konfigurationsdatei von Kibana unter /etc/kibana/kibana.yml, um sie zu bearbeiten.
$ sudo nano /etc/kibana/kibana.yml
Füge den Code aus dem vorherigen Befehl am Ende der Datei ein.
. . . # Maximum number of documents loaded by each shard to generate autocomplete suggestions. # This value must be a whole number greater than zero. Defaults to 100_000 #unifiedSearch.autocomplete.valueSuggestions.terminateAfter: 100000 xpack.encryptedSavedObjects.encryptionKey: 3ff21c6daf52ab73e932576c2e981711 xpack.reporting.encryptionKey: edf9c3863ae339bfbd48c713efebcfe9 xpack.security.encryptionKey: 7841fd0c4097987a16c215d9429daec1
Kopiere die CA-Zertifikatsdatei /etc/elasticsearch/certs/http_ca.crt in das Verzeichnis /etc/kibana.
$ sudo cp /etc/elasticsearch/certs/http_ca.crt /etc/kibana/
Kibana-Host konfigurieren
Kibana muss so konfiguriert werden, dass es über die private IP-Adresse des Servers erreichbar ist. Suche die Zeile #server.host: "localhost" in der Datei und füge die folgende Zeile wie gezeigt direkt darunter ein.
# Kibana is served by a back end server. This setting specifies the port to use. #server.port: 5601 # Specifies the address to which the Kibana server will bind. IP addresses and host names are both valid values. # The default is 'localhost', which usually means remote machines will not be able to connect. # To allow connections from remote users, set this parameter to a non-loopback address. #server.host: "localhost" server.host: "your_private_IP"
Telemetrie ausschalten
Kibana sendet standardmäßig Daten an seine Server zurück. Das kann die Leistung beeinträchtigen und stellt außerdem ein Datenschutzrisiko dar. Deshalb solltest du die Telemetrie ausschalten. Füge den folgenden Code am Ende der Datei ein, um die Telemetrie zu deaktivieren. Die erste Einstellung schaltet die Telemetrie aus und die zweite Einstellung verbietet das Überschreiben der ersten Einstellung im Abschnitt Erweiterte Einstellungen in Kibana.
telemetry.optIn: false telemetry.allowChangingOptInStatus: false
Wenn du fertig bist, speichere die Datei, indem du Strg + X drückst und Y eingibst, wenn du dazu aufgefordert wirst.
SSL konfigurieren
Finde die Variable elasticsearch.ssl.certificateAuthorities, entkommentiere sie und ändere ihren Wert wie unten gezeigt.
elasticsearch.ssl.certificateAuthorities: [ "/etc/kibana/http_ca.crt" ]
Kibana-Zugang konfigurieren
Der nächste Schritt ist die Erstellung eines Anmeldetokens, mit dem wir uns später in der Kibana-Weboberfläche anmelden werden.
$ sudo /usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s kibana eyJ2ZXIiOiI4LjEwLjIiLCJhZHIiOlsiMTU5LjIyMy4yMjAuMjI4OjkyMDAiXSwiZmdyIjoiOGMyYTcyYmUwMDg5NTJlOGMxMWUwNDgzYjE2OTcwOTMxZWZlNzYyMDAwNzhhOGMwNTNmNWU0NGJiY2U4NzcwMSIsImtleSI6IlQ5eE0tNG9CUWZDaGdaakUwbFAzOk9QTU5uWVRnUWppU3lvU0huOUoyMHcifQ==
Kibana starten
Nachdem du nun den sicheren Zugang und das Netzwerk für Kibana konfiguriert hast, starte den Prozess und aktiviere ihn.
$ sudo systemctl enable kibana --now
Überprüfe den Status, um zu sehen, ob der Prozess läuft.
$ sudo systemctl status kibana
? kibana.service - Kibana
Loaded: loaded (/lib/systemd/system/kibana.service; enabled; preset: enabled)
Active: active (running) since Wed 2023-10-04 15:27:28 UTC; 9s ago
Docs: https://www.elastic.co
Main PID: 2686 (node)
Tasks: 11 (limit: 4652)
Memory: 241.5M
CPU: 9.902s
CGroup: /system.slice/kibana.service
??2686 /usr/share/kibana/bin/../node/bin/node /usr/share/kibana/bin/../src/cli/dist
Oct 04 15:27:28 kibana systemd[1]: Started kibana.service - Kibana.
Schritt 10 – Filebeat installieren und konfigurieren
Es ist wichtig zu wissen, dass wir Filebeat auf dem Suricata-Server installieren werden. Wechsle also dorthin zurück und füge den Elastic GPG-Schlüssel hinzu, um loszulegen.
$ wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo gpg --dearmor -o /usr/share/keyrings/elasticsearch-keyring.gpg
Erstelle das Elastic Repository.
$ echo "deb [signed-by=/usr/share/keyrings/elasticsearch-keyring.gpg] https://artifacts.elastic.co/packages/8.x/apt stable main" | sudo tee /etc/apt/sources.list.d/elastic-8.x.list
Aktualisiere die Liste der System-Repositorys.
$ sudo apt update
Speichere die Datei, indem du Strg + X drückst und Y eingibst, wenn du dazu aufgefordert wirst.
Installiere Filebeat.
$ sudo apt install filebeat
Bevor wir Filebeat konfigurieren, müssen wir die Datei http_ca.crt vom Elasticsearch-Server auf den Filebeat-Server kopieren. Führe den folgenden Befehl auf dem Filebeat-Server aus.
$ scp username@your_public_ip:/etc/elasticsearch/certs/http_ca.crt /etc/filebeat
Filebeat speichert seine Konfiguration in der Datei /etc/filebeat/filebeat.yml. Öffne sie zur Bearbeitung.
$ sudo nano /etc/filebeat/filebeat.yml
Als Erstes musst du sie mit dem Dashboard von Kibana verbinden. Suche die Zeile #host: "localhost:5601" im Abschnitt Kibana und füge die folgenden Zeilen direkt darunter ein, wie gezeigt.
. . . # Starting with Beats version 6.0.0, the dashboards are loaded via the Kibana API. # This requires a Kibana endpoint configuration. setup.kibana: # Kibana Host # Scheme and port can be left out and will be set to the default (http and 5601) # In case you specify and additional path, the scheme is required: http://localhost:5601/path # IPv6 addresses should always be defined as: https://[2001:db8::1]:5601 #host: "localhost:5601" host: "your_private_IP:5601" protocol: "http" ssl.enabled: true ssl.certificate_authorities: ["/etc/filebeat/http_ca.crt"] . . .
Als Nächstes suchst du den Abschnitt “ Elasticsearch Output“ in der Datei und bearbeitest die Werte von hosts, protocol, username und password wie unten gezeigt. Für den Benutzernamen wählst du den Wert elastic und für das Passwort den Wert, den du in Schritt 8 dieses Lernprogramms erstellt hast.
output.elasticsearch: # Array of hosts to connect to. hosts: ["your_private_IP:9200"] # Protocol - either `http` (default) or `https`. protocol: "https" # Authentication credentials - either API key or username/password. #api_key: "id:api_key" username: "elastic" password: "bd1YJfhSa8RC8SMvTIwg" ssl.certificate_authorities: ["/etc/filebeat/http_ca.crt"] ssl.verification_mode: full . . .
Füge die folgende Zeile am Ende der Datei ein.
setup.ilm.overwrite: true
Wenn du fertig bist, speichere die Datei, indem du Strg + X drückst und Y eingibst, wenn du dazu aufgefordert wirst. Es gibt noch einen weiteren Schritt, um sicherzustellen, dass sich Filebeat mit Elasticsearch verbindet. Wir müssen die SSL-Informationen von Elasticsearch an Filebeat weitergeben, damit die Verbindung hergestellt werden kann.
Teste die Verbindung zwischen Filebeat und dem Elasticsearch-Server. Du wirst nach deinem Elasticsearch-Passwort gefragt.
$ curl -v --cacert /etc/filebeat/http_ca.crt https://your_private_ip:9200 -u elastic
Du wirst die folgende Ausgabe erhalten.
Enter host password for user 'elastic':
* Trying 10.133.0.2:9200...
* Connected to 10.133.0.2 (10.133.0.2) port 9200 (#0)
* ALPN: offers h2,http/1.1
* TLSv1.3 (OUT), TLS handshake, Client hello (1):
* CAfile: /etc/filebeat/http_ca.crt
* CApath: /etc/ssl/certs
* TLSv1.3 (IN), TLS handshake, Server hello (2):
* TLSv1.3 (IN), TLS handshake, Encrypted Extensions (8):
* TLSv1.3 (IN), TLS handshake, Certificate (11):
* TLSv1.3 (IN), TLS handshake, CERT verify (15):
* TLSv1.3 (IN), TLS handshake, Finished (20):
* TLSv1.3 (OUT), TLS change cipher, Change cipher spec (1):
* TLSv1.3 (OUT), TLS handshake, Finished (20):
* SSL connection using TLSv1.3 / TLS_AES_256_GCM_SHA384
* ALPN: server did not agree on a protocol. Uses default.
* Server certificate:
* subject: CN=kibana
* start date: Oct 4 14:28:33 2023 GMT
* expire date: Oct 3 14:28:33 2025 GMT
* subjectAltName: host "10.133.0.2" matched cert's IP address!
* issuer: CN=Elasticsearch security auto-configuration HTTP CA
* SSL certificate verify ok.
* using HTTP/1.x
* Server auth using Basic with user 'elastic'
> GET / HTTP/1.1
> Host: 10.133.0.2:9200
> Authorization: Basic ZWxhc3RpYzpsaWZlc3Vja3M2NjIwMDI=
> User-Agent: curl/7.88.1
> Accept: */*
>
* TLSv1.3 (IN), TLS handshake, Newsession Ticket (4):
< HTTP/1.1 200 OK
< X-elastic-product: Elasticsearch
< content-type: application/json
< content-length: 530
<
{
"name" : "kibana",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "KGYx4poLSxKhPyOlYrMq1g",
"version" : {
"number" : "8.10.2",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "6d20dd8ce62365be9b1aca96427de4622e970e9e",
"build_date" : "2023-09-19T08:16:24.564900370Z",
"build_snapshot" : false,
"lucene_version" : "9.7.0",
"minimum_wire_compatibility_version" : "7.17.0",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "You Know, for Search"
}
* Connection #0 to host 10.133.0.2 left intact
Als Nächstes aktivierst du das in Filebeat integrierte Suricata-Modul.
$ sudo filebeat modules enable suricata
Öffne die Datei /etc/filebeat/modules.d/suricata.yml zum Bearbeiten.
$ sudo nano /etc/filebeat/modules.d/suricata.yml
Bearbeite die Datei wie unten gezeigt. Du musst den Wert der Variable enabled in true ändern. Entferne außerdem die Kommentierung der Variable var.paths und setze ihren Wert wie gezeigt.
# Module: suricata
# Docs: https://www.elastic.co/guide/en/beats/filebeat/8.10/filebeat-module-suricata.html
- module: suricata
# All logs
eve:
enabled: true
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
var.paths: ["/var/log/suricata/eve.json"]
Wenn du fertig bist, speichere die Datei, indem du Strg + X drückst und Y eingibst, wenn du dazu aufgefordert wirst.
Der letzte Schritt bei der Konfiguration von Filebeat besteht darin, die SIEM-Dashboards und -Pipelines mit dem Befehl filebeat setup in Elasticsearch zu laden.
$ sudo filebeat setup
Es kann ein paar Minuten dauern, bis der Befehl ausgeführt wird. Sobald er fertig ist, solltest du die folgende Ausgabe erhalten.
Overwriting ILM policy is disabled. Set `setup.ilm.overwrite: true` for enabling. Index setup finished. Loading dashboards (Kibana must be running and reachable) Loaded dashboards Loaded Ingest pipelines
Starten Sie den Filebeat-Dienst.
$ sudo systemctl start filebeat
Überprüfe den Status des Dienstes.
$ sudo systemctl status filebeat
Schritt 11 – Zugriff auf das Kibana Dashboard
Da KIbana so konfiguriert ist, dass es nur über seine private IP-Adresse auf Elasticsearch zugreift, hast du zwei Möglichkeiten, darauf zuzugreifen. Die erste Methode ist, von deinem PC aus einen SSH-Tunnel zum Elasticsearch-Server zu benutzen. Dadurch wird Port 5601 von deinem PC an die private IP-Adresse des Servers weitergeleitet und du kannst von deinem PC aus über http://localhost:5601 auf Kibana zugreifen. Diese Methode bedeutet jedoch, dass du von keinem anderen Ort aus darauf zugreifen kannst.
Die andere Möglichkeit ist, Nginx auf deinem Suricata-Server zu installieren und ihn als Reverse Proxy zu benutzen, um über die private IP-Adresse auf den Elasticsearch-Server zuzugreifen. Wir werden beide Möglichkeiten besprechen. Du kannst dich je nach deinen Anforderungen für einen der beiden Wege entscheiden.
Lokalen SSH-Tunnel verwenden
Wenn du Windows 10 oder Windows 11 verwendest, kannst du den SSH LocalTunnel über deine Windows Powershell ausführen. Unter Linux oder macOS kannst du das Terminal verwenden. Wahrscheinlich musst du den SSH-Zugang konfigurieren, falls du das nicht schon getan hast.
Führe den folgenden Befehl im Terminal deines Computers aus, um den SSH-Tunnel zu erstellen.
$ ssh -L 5601:your_private_IP:5601 navjot@your_public_IP -N
- Das
-LFlag bezieht sich auf den lokalen SSH-Tunnel, der den Datenverkehr vom Port deines PCs zum Server weiterleitet. private_IP:5601ist die IP-Adresse, an die dein Datenverkehr auf dem Server weitergeleitet wird. In diesem Fall ersetzt du sie durch die private IP-Adresse deines Elasticsearch-Servers.your_public_IPist die öffentliche IP-Adresse des Elasticsearch-Servers, die zum Öffnen einer SSH-Verbindung verwendet wird.- Das
-NFlag weist OpenSSH an, keinen Befehl auszuführen, sondern die Verbindung so lange aufrecht zu erhalten, wie der Tunnel läuft.
Jetzt, da der Tunnel geöffnet ist, kannst du auf Kibana zugreifen, indem du die URL http://localhost:5601 im Browser deines PCs öffnest. Du erhältst den folgenden Bildschirm.
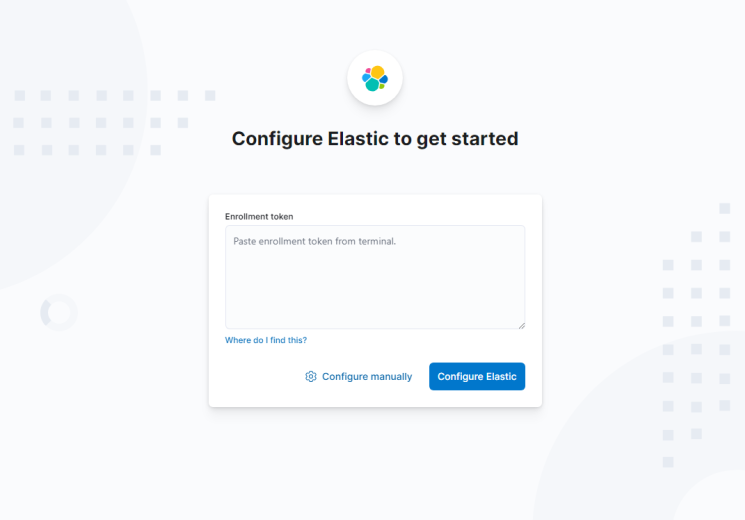
Du musst den Befehl so lange laufen lassen, wie du auf Kibana zugreifen willst. Drücke Strg + C in deinem Terminal, um den Tunnel zu schließen.
Nginx Reverse-Proxy verwenden
Diese Methode ist am besten geeignet, wenn du von überall auf der Welt auf das Dashboard zugreifen willst.
Firewall konfigurieren
Bevor du weitermachst, musst du HTTP- und HTTPS-Ports in der Firewall öffnen.
$ sudo ufw allow http $ sudo ufw allow https
Nginx installieren
Debian 12 wird mit einer älteren Version von Nginx ausgeliefert. Um die neueste Version zu installieren, musst du das offizielle Nginx-Repository herunterladen.
Importiere den Signierschlüssel von Nginx.
$ curl https://nginx.org/keys/nginx_signing.key | gpg --dearmor \ | sudo tee /usr/share/keyrings/nginx-archive-keyring.gpg >/dev/null
Füge das Repository für die stabile Version von Nginx hinzu.
$ echo "deb [signed-by=/usr/share/keyrings/nginx-archive-keyring.gpg] \
http://nginx.org/packages/debian `lsb_release -cs` nginx" \
| sudo tee /etc/apt/sources.list.d/nginx.list
Aktualisiere die System-Repositories.
$ sudo apt update
Installiere Nginx.
$ sudo apt install nginx
Überprüfe die Installation. Da wir mit Debian arbeiten, ist der sudo im Befehl wichtig.
$ sudo nginx -v nginx version: nginx/1.24.0
Starte den Nginx-Server.
$ sudo systemctl start nginx
SSL installieren und konfigurieren
Der erste Schritt ist die Installation des Let’s Encrypt SSL-Zertifikats. Wir müssen Certbot installieren, um das SSL-Zertifikat zu erstellen. Du kannst Certbot entweder über das Repository von Debian installieren oder die neueste Version mit dem Snapd-Tool herunterladen. Wir werden die Snapd-Version verwenden.
Bei Debian 12 ist Snapd noch nicht installiert. Installiere das Snapd-Paket.
$ sudo apt install snapd
Führe die folgenden Befehle aus, um sicherzustellen, dass deine Version von Snapd auf dem neuesten Stand ist.
$ sudo snap install core && sudo snap refresh core
Installiere Certbot.
$ sudo snap install --classic certbot
Verwende den folgenden Befehl, um sicherzustellen, dass der Certbot-Befehl ausgeführt werden kann, indem du einen symbolischen Link zum Verzeichnis /usr/bin erstellst.
$ sudo ln -s /snap/bin/certbot /usr/bin/certbot
Bestätige die Installation von Certbot.
$ certbot --version certbot 2.7.0
Erstelle das SSL-Zertifikat für die Domain kibana.example.com.
$ sudo certbot certonly --nginx --agree-tos --no-eff-email --staple-ocsp --preferred-challenges http -m name@example.com -d kibana.example.com
Mit dem obigen Befehl wird ein Zertifikat in das Verzeichnis /etc/letsencrypt/live/kibana.example.com auf deinem Server heruntergeladen.
Erstelle ein Diffie-Hellman-Gruppenzertifikat.
$ sudo openssl dhparam -dsaparam -out /etc/ssl/certs/dhparam.pem 4096
Um zu überprüfen, ob die SSL-Erneuerung einwandfrei funktioniert, führe einen Probelauf des Prozesses durch.
$ sudo certbot renew --dry-run
Wenn du keine Fehler siehst, ist alles in Ordnung. Dein Zertifikat wird automatisch erneuert.
Nginx konfigurieren
Erstelle und öffne die Nginx-Konfigurationsdatei für Kibana.
$ sudo nano /etc/nginx/conf.d/kibana.conf
Füge den folgenden Code in die Datei ein. Ersetze die IP-Adresse durch die private IP-Adresse deines Elasticsearch-Servers.
server {
listen 80; listen [::]:80;
server_name kibana.example.com;
return 301 https://$host$request_uri;
}
server {
server_name kibana.example.com;
charset utf-8;
listen 443 ssl http2;
listen [::]:443 ssl http2;
access_log /var/log/nginx/kibana.access.log;
error_log /var/log/nginx/kibana.error.log;
ssl_certificate /etc/letsencrypt/live/kibana.example.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/kibana.example.com/privkey.pem;
ssl_trusted_certificate /etc/letsencrypt/live/kibana.example.com/chain.pem;
ssl_session_timeout 1d;
ssl_session_cache shared:MozSSL:10m;
ssl_session_tickets off;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384;
resolver 8.8.8.8;
ssl_stapling on;
ssl_stapling_verify on;
ssl_dhparam /etc/ssl/certs/dhparam.pem;
location / {
proxy_pass http://your_private_IP:5601;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
Speichere die Datei, indem du Strg + X drückst und Y eingibst, wenn du dazu aufgefordert wirst.
Öffne die Datei /etc/nginx/nginx.conf zum Bearbeiten.
$ sudo nano /etc/nginx/nginx.conf
Füge die folgende Zeile vor der Zeile include /etc/nginx/conf.d/*.conf; ein.
server_names_hash_bucket_size 64;
Speichere die Datei, indem du Strg + X drückst und Y eingibst, wenn du dazu aufgefordert wirst.
Überprüfe die Konfiguration.
$ sudo nginx -t nginx: the configuration file /etc/nginx/nginx.conf syntax is ok nginx: configuration file /etc/nginx/nginx.conf test is successful
Starte den Nginx-Dienst neu.
$ sudo systemctl restart nginx
Dein Kibana-Dashboard sollte über die URL https://kibana.example.com von jedem beliebigen Ort aus zugänglich sein.
Schritt 12 – Kibana Dashboards verwalten
Bevor du mit der Verwaltung der Dashboards fortfährst, musst du das Basis-URL-Feld in der Kibana-Konfiguration hinzufügen.
Öffne die Konfigurationsdatei von Kibana.
$ sudo nano /etc/kibana/kibana.yml
Suche die auskommentierte Zeile #server.publicBaseUrl: "" und ändere sie wie folgt, indem du die Raute davor entfernst.
server.publicBaseUrl: "https://kibana.example.com"
Speichere die Datei, indem du Strg + X drückst und Y eingibst, wenn du dazu aufgefordert wirst.
Starte den Kibana-Dienst neu.
$ sudo systemctl restart kibana
Warte ein paar Minuten und lade die URL https://kibana.example.com in deinem Browser. Du erhältst das Feld für das Anmeldetoken. Gib das Enrollment-Token ein, das du in Schritt 9 erstellt hast.
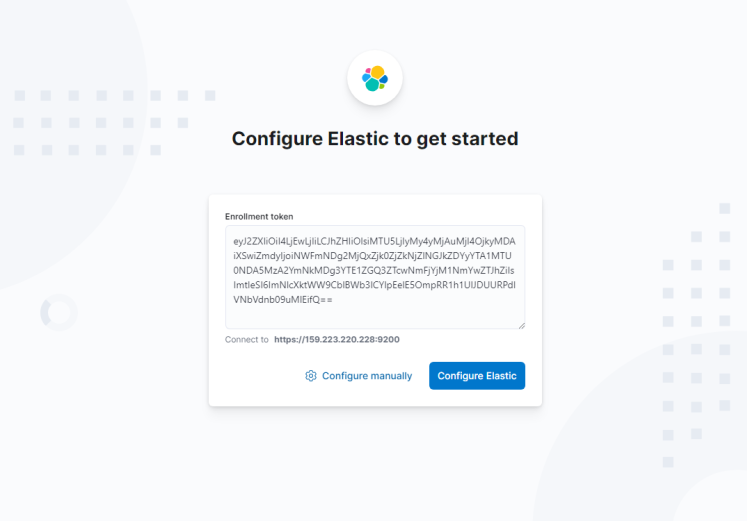
Klicke auf die Schaltfläche Configure Elastic, um fortzufahren. Als nächstes wirst du nach dem Verifizierungscode gefragt.
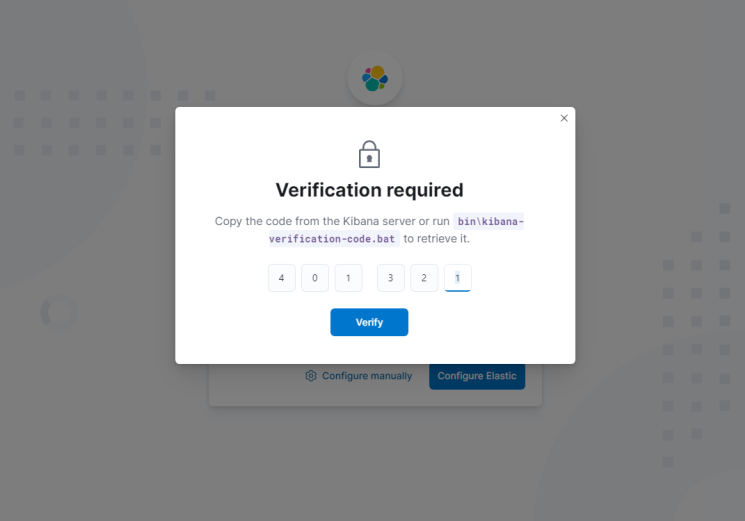
Wechsle zurück zum Elasticsearch-Terminal und führe den folgenden Befehl aus, um den Code zu generieren. Gib diesen Code auf der Seite ein und klicke auf die Schaltfläche Verifizieren, um fortzufahren.
$ sudo /usr/local/share/kibana/bin/kibana-verification-code
Warte nun, bis die Elastic-Einrichtung abgeschlossen ist. Das kann einige Minuten dauern.

Danach wirst du zum Anmeldebildschirm weitergeleitet.
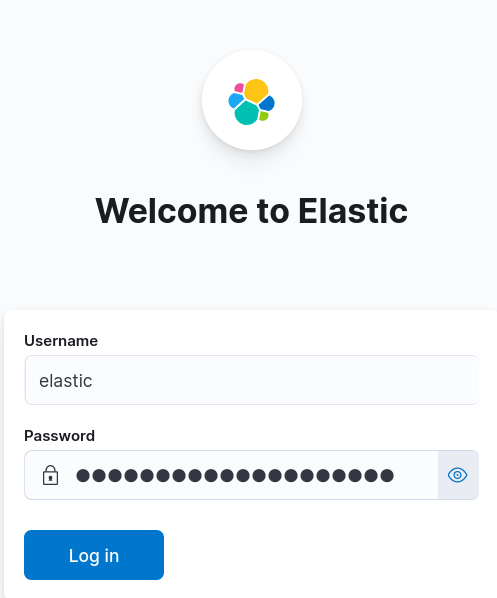
Melde dich mit dem Benutzernamen elastic und dem Passwort an, das du zuvor erstellt hast.
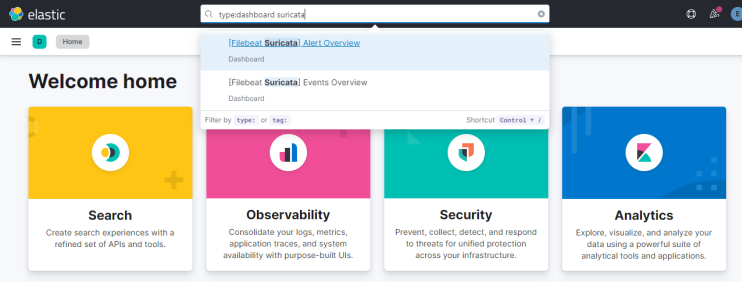
Gib oben in das Suchfeld type:data suricata ein, um die Informationen von Suricata zu finden.
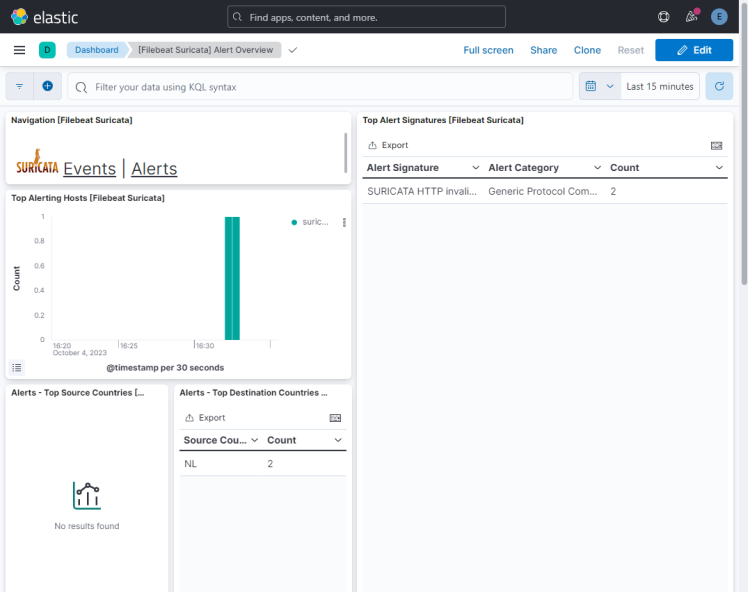
Klicke auf das erste Ergebnis ([Filebeat Suricata] Alert Overview) und du erhältst einen Bildschirm ähnlich dem folgenden. Standardmäßig werden hier nur die Einträge der letzten 15 Minuten angezeigt, aber wir zeigen einen größeren Zeitraum an, um mehr Daten für den Lehrgang zu zeigen.
Klicke auf die Schaltfläche Ereignisse, um alle protokollierten Ereignisse anzuzeigen.
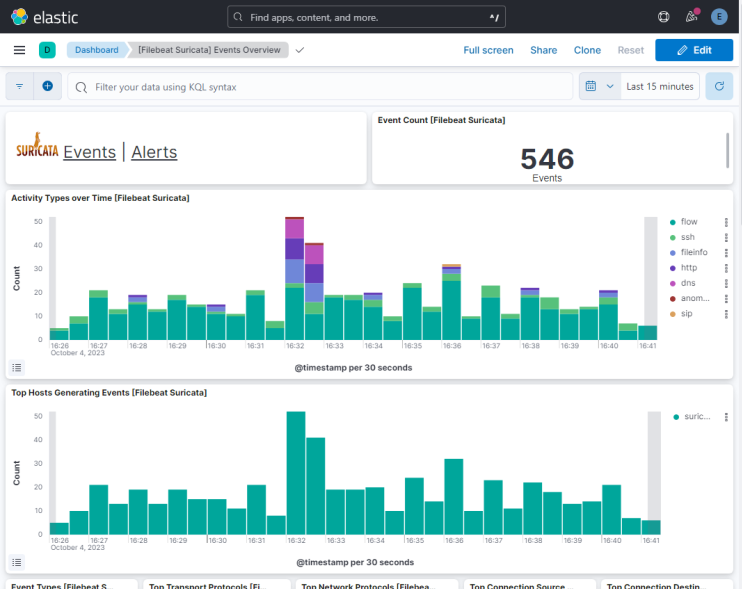
Wenn du auf den Ereignis- und Warnungsseiten nach unten scrollst, kannst du jedes Ereignis und jede Warnung anhand der Art des Protokolls, des Quell- und Zielports und der IP-Adresse der Quelle identifizieren. Du kannst dir auch die Länder ansehen, aus denen der Datenverkehr stammt.
Du kannst Kibana und Filebeat nutzen, um auf andere Arten von Dashboards zuzugreifen und diese zu erstellen. Eines der nützlichen eingebauten Dashboards, das du sofort nutzen kannst, ist das Sicherheits-Dashboard. Klicke im linken Hamburger-Menü auf das Menü Sicherheit >> Erkunden.
Auf der nächsten Seite wählst du die Option Netzwerk, um das zugehörige Dashboard zu öffnen.
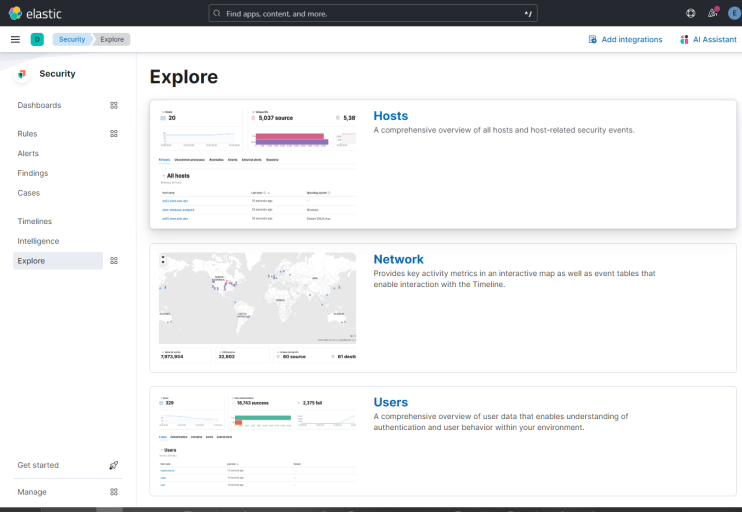
Wenn du auf die Option Netzwerk klickst, erhältst du den folgenden Bildschirm.
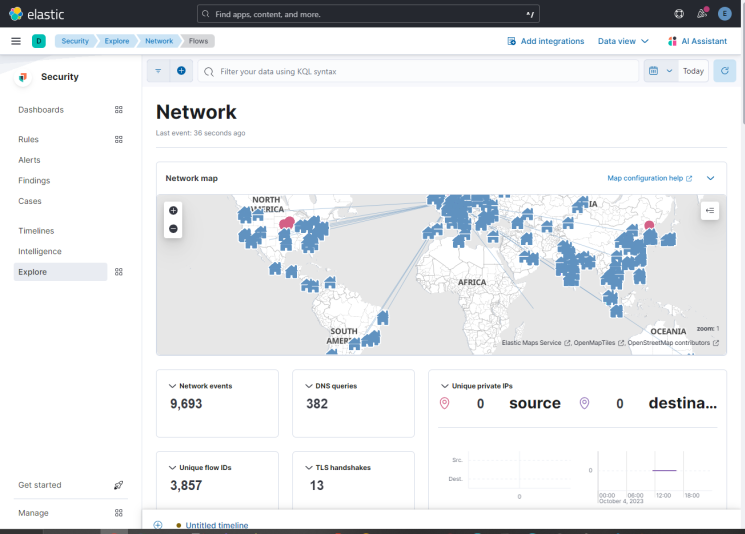
Du kannst weitere Dashboards wie Nginx hinzufügen, indem du die eingebauten Filebeat-Module aktivierst und konfigurierst.
Fazit
Damit ist die Anleitung zur Installation und Konfiguration von Suricata IDS mit Elastic Stack auf einem Debian 12 Server abgeschlossen. Außerdem hast du Nginx als Reverse Proxy konfiguriert, um von außen auf Kibana Dashboards zuzugreifen. Wenn du Fragen hast, schreibe sie unten in die Kommentare.