So installierst du den TIG Stack (Telegraf, InfluxDB und Grafana) auf Rocky Linux
Der TIG (Telegraf, InfluxDB und Grafana) Stack ist ein Akronym für eine Plattform von Open-Source-Tools, die das Sammeln, Speichern, Darstellen und Alarmieren von Systemmetriken erleichtern. Du kannst Metriken wie Arbeitsspeicher, Festplattenplatz, angemeldete Benutzer, Systemauslastung, Swap-Nutzung, Betriebszeit, laufende Prozesse usw. von einem Ort aus überwachen und visualisieren. Die im Stack verwendeten Tools sind wie folgt
- Telegraf – ist ein Open-Source-Metriken-Sammel-Agent zum Sammeln und Senden von Daten und Ereignissen aus Datenbanken, Systemen und IoT-Sensoren. Es unterstützt verschiedene Output-Plugins wie InfluxDB, Graphite, Kafka usw., an die es die gesammelten Daten senden kann.
- InfluxDB – ist eine Open-Source-Zeitreihendatenbank, die in der Sprache Go geschrieben wurde. Sie ist für schnelle, hochverfügbare Speicherung optimiert und eignet sich für alles, was mit großen Mengen an Zeitstempeldaten zu tun hat, einschließlich Metriken, Ereignissen und Echtzeitanalysen.
- Grafana – ist eine Open-Source-Datenvisualisierungs- und Monitoring-Suite. Sie unterstützt verschiedene Input-Plugins wie Graphite, ElasticSearch, InfluxDB usw. Sie bietet ein wunderschönes Dashboard und Metrik-Analysen, mit denen du jede Art von Systemmetrik und Leistungsdaten visualisieren und überwachen kannst.
In diesem Lernprogramm erfährst du, wie du den TIG Stack auf einem einzelnen Rocky Linux 8 basierten Server installierst und konfigurierst.
Voraussetzungen
- Ein Server, auf dem Rocky Linux 8 läuft.
- Ein Nicht-Sudo-Benutzer mit Root-Rechten.
- Deaktiviertes SELinux.
- Stelle sicher, dass alles auf dem neuesten Stand ist.
$ sudo dnf update
Schritt 1 – Firewall konfigurieren
Der erste Schritt besteht darin, die Firewall zu konfigurieren. Rocky Linux wird mit der Firewall Firewalld ausgeliefert.
Überprüfe, ob die Firewall läuft.
$ sudo firewall-cmd --state
Du solltest die folgende Ausgabe erhalten.
running
Überprüfe die aktuell erlaubten Dienste/Ports.
$ sudo firewall-cmd --permanent --list-services
Es sollte die folgende Ausgabe erscheinen.
cockpit dhcpv6-client ssh
Erlaube den Port 8086 für InfluxDB und den Port 3000 für den Grafana Server.
$ sudo firewall-cmd --permanent --add-port=8086/tcp
$ sudo firewall-cmd --permanent --add-port=3000/tcp
Lade die Firewall neu.
$ sudo systemctl reload firewalld
Schritt 2 – Installiere InfluxDB
Um InfluxDB zu installieren, musst du zunächst eine Repo-Datei dafür erstellen.
Erstelle und öffne die Datei influxdb.repo zum Bearbeiten.
$ sudo nano /etc/yum.repos.d/influxdb.repo
Füge den folgenden Code in die Datei ein.
[influxdb]
name = InfluxDB Repository - RHEL $releasever
baseurl = https://repos.influxdata.com/rhel/$releasever/$basearch/stable
enabled = 1
gpgcheck = 1
gpgkey = https://repos.influxdata.com/influxdb.key
Speichere die Datei, indem du Strg + X drückst und Y eingibst, wenn du dazu aufgefordert wirst.
Du hast die Möglichkeit, InfluxDB 1.8.x oder 2.0.x zu installieren. Es ist jedoch besser, die neueste Version zu verwenden. Installiere InfluxDB.
$ sudo dnf install influxdb2
Starte und aktiviere den InfluxDB-Dienst.
$ sudo systemctl enable influxdb
$ sudo systemctl start influxdb
Schritt 3 – InfluxDB-Datenbank und Benutzeranmeldeinformationen erstellen
Um die Daten von Telegraf zu speichern, musst du die Influx-Datenbank und den Benutzer einrichten.
InfluxDB wird mit einem Kommandozeilentool namens influx geliefert, mit dem du mit dem InfluxDB-Server interagieren kannst. Stell dir influx als das mysql Kommandozeilentool vor.
Führe den folgenden Befehl aus, um die erste Konfiguration für Influx vorzunehmen.
$ influx setup
> Welcome to InfluxDB 2.0!
? Please type your primary username navjot
? Please type your password ***************
? Please type your password again ***************
? Please type your primary organization name howtoforge
? Please type your primary bucket name tigstack
? Please type your retention period in hours, or 0 for infinite 360
? Setup with these parameters?
Username: navjot
Organization: howtoforge
Bucket: tigstack
Retention Period: 360h0m0s
Yes
> Config default has been stored in /home/username/.influxdbv2/configs.
User Organization Bucket
navjot howtoforge tigstack
Du musst deinen anfänglichen Benutzernamen, dein Passwort, den Namen deiner Organisation, den Namen des primären Buckets, in dem die Daten gespeichert werden, und die Aufbewahrungszeit in Stunden für diese Daten festlegen.
Du kannst diese Einstellungen auch vornehmen, indem du die URL http://<serverIP>:8086/ in deinem Browser aufrufst. Sobald du die Ersteinrichtung durchgeführt hast, kannst du dich bei der URL einloggen.

Du wirst mit dem folgenden Dashboard begrüßt.
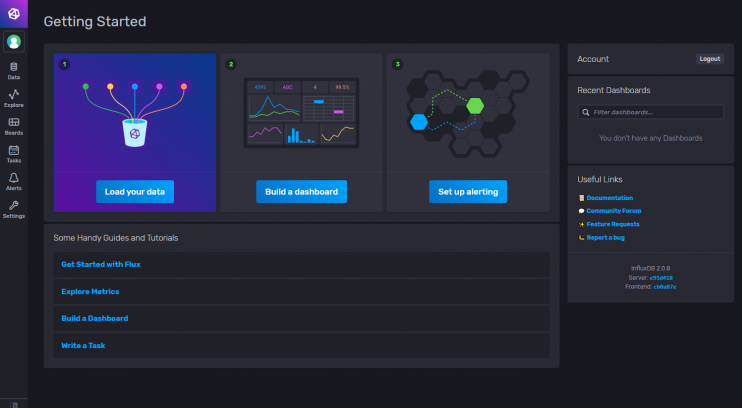
Bei der Ersteinrichtung wird ein Standard-Token erstellt, der vollen Lese- und Schreibzugriff auf alle Organisationen in der Datenbank hat. Aus Sicherheitsgründen benötigst du ein neues Token, das sich nur mit der Organisation und dem Bucket verbindet, mit denen wir uns verbinden wollen.
Um ein neues Token zu erstellen, klicke in der linken Seitenleiste auf die Option Daten. Dann klickst du auf den Abschnitt Token.
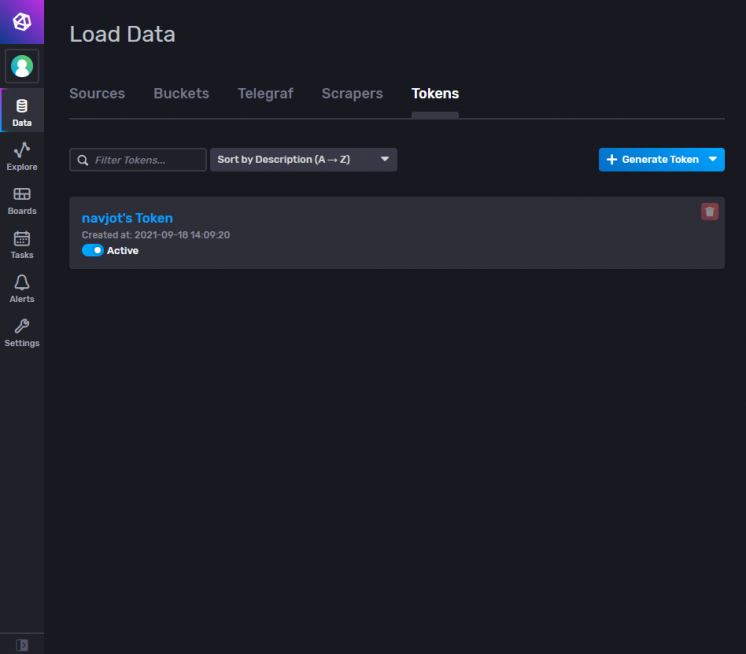
Hier siehst du den Standard-Token, den wir bei der Erstkonfiguration erstellt haben. Klicke auf die Schaltfläche Token generieren und wähle die Option Token lesen/schreiben, um ein neues Overlay-Popup zu öffnen.
Gib dem Token einen Namen und wähle den Standard-Bucket, den wir in den Abschnitten Lesen und Schreiben erstellt haben.
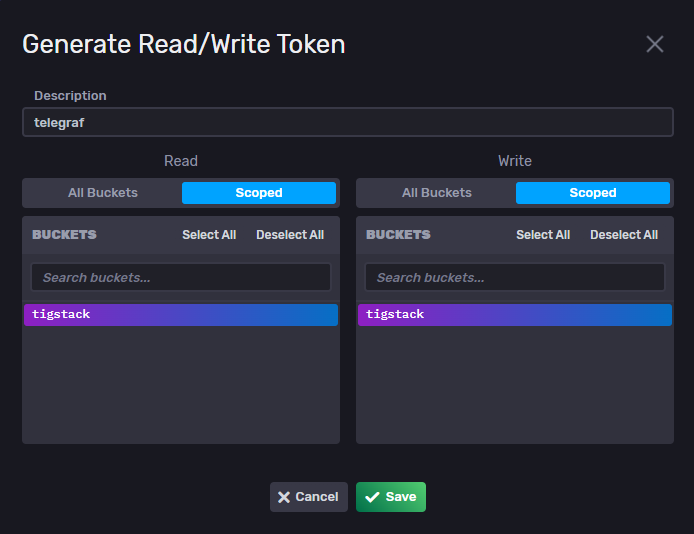
Klicke auf Speichern, um die Erstellung des Tokens abzuschließen. Klicke auf den Namen des neu erstellten Tokens, um ein Popup mit dem Wert des Tokens zu öffnen. Speichere ihn für den Moment, da wir ihn später noch brauchen werden.
Damit ist die Installation und Konfiguration von InfluxDB abgeschlossen. Als Nächstes müssen wir Telegraf installieren.
Schritt 4 – Telegraf installieren
Telegraf und InfluxDB teilen sich das gleiche Repository. Das heißt, du kannst Telegraf direkt installieren.
$ sudo dnf install telegraf
Aktiviere und starte den Telegraf-Dienst.
$ sudo systemctl enable telegraf
$ sudo systemctl start telegraf
Telegraf ist ein Plugin-gesteuerter Agent und verfügt über 4 Arten von Plugins:
- Input-Plugins sammeln Metriken.
- Prozessor-Plugins transformieren, dekorieren und filtern Metriken.
- Aggregator-Plugins erstellen und aggregieren Metriken.
- Output-Plugins definieren die Ziele, an die die Metriken gesendet werden, einschließlich InfluxDB.
Telegraf speichert seine Konfiguration für alle diese Plugins in der Datei /etc/telegraf/telegraf.conf. Der erste Schritt besteht darin, Telegraf mit InfluxDB zu verbinden, indem du das Output-Plugin influxdb_v2 aktivierst. Öffne die Datei /etc/telegraf/telegraf.conf zum Bearbeiten.
$ sudo nano /etc/telegraf/telegraf.conf
Finde die Zeile [[outputs.influxdb_v2]] und kommentiere sie aus, indem du das # davor entfernst. Bearbeite den Code darunter auf folgende Weise.
[[outputs.influxdb_v2]]
urls = ["http://localhost:8086"]
token = "$INFLUX_TOKEN"
organization = "howtoforge"
bucket = "tigstack"
Füge den zuvor gespeicherten Wert des InfluxDB-Tokens anstelle der Variable $INFLUX_TOKEN in den obigen Code ein.
Suche nach der Zeile INPUT PLUGINS und du wirst sehen, dass die folgenden Eingabe-Plugins standardmäßig aktiviert sind.
# Read metrics about cpu usage
[[inputs.cpu]]
## Whether to report per-cpu stats or not
percpu = true
## Whether to report total system cpu stats or not
totalcpu = true
## If true, collect raw CPU time metrics
collect_cpu_time = false
## If true, compute and report the sum of all non-idle CPU states
report_active = false
# Read metrics about disk usage by mount point
[[inputs.disk]]
## By default stats will be gathered for all mount points.
## Set mount_points will restrict the stats to only the specified mount points.
# mount_points = ["/"]
## Ignore mount points by filesystem type.
ignore_fs = ["tmpfs", "devtmpfs", "devfs", "iso9660", "overlay", "aufs", "squashfs"]
[[inputs.diskio]]
....
....
# Get kernel statistics from /proc/stat
[[inputs.kernel]]
# no configuration
# Read metrics about memory usage
[[inputs.mem]]
# no configuration
# Get the number of processes and group them by status
[[inputs.processes]]
# no configuration
# Read metrics about swap memory usage
[[inputs.swap]]
# no configuration
# Read metrics about system load & uptime
[[inputs.system]]
## Uncomment to remove deprecated metrics.
Du kannst je nach Bedarf weitere Input-Plugins konfigurieren, z. B. Apache Server, Docker-Container, Elasticsearch, iptables firewall, Kubernetes, Memcached, MongoDB, MySQL, Nginx, PHP-fpm, Postfix, RabbitMQ, Redis, Varnish, Wireguard, PostgreSQL, usw.
Wenn du fertig bist, speichere die Datei, indem du Strg + X drückst und Y eingibst, wenn du dazu aufgefordert wirst.
Starte den Telegraf-Dienst neu, nachdem du die Änderungen vorgenommen hast.
$ sudo systemctl restart telegraf
Schritt 5 – Überprüfe, ob die Telegraf-Statistiken in InfluxDB gespeichert werden
Bevor du fortfährst, musst du überprüfen, ob die Telegraf-Statistiken korrekt erfasst und in die InfluxDB eingespeist werden. Öffne die InfluxDB UI in deinem Browser und besuche Daten >> Buckets >> tigstack. Du solltest die folgende Seite angezeigt bekommen.
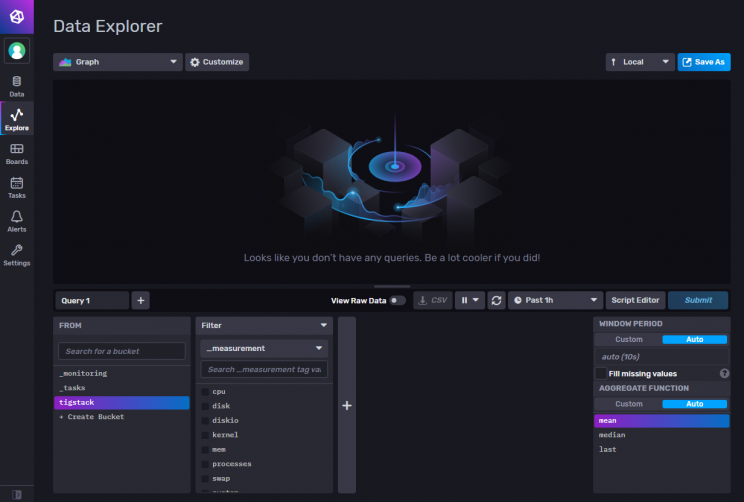
Klicke auf den Bucket-Namen und dann auf einen der Werte im Filter _measurement und klicke immer wieder auf andere Werte, wenn sie erscheinen. Wenn du fertig bist, klicke auf die Schaltfläche Senden. Oben solltest du ein Diagramm sehen.

Dies sollte bestätigen, dass die Daten korrekt weitergegeben werden.
Schritt 6 – Grafana installieren
Erstelle und öffne die Datei /etc/yum.repos.d/grafana.repo zum Bearbeiten.
$ sudo nano /etc/yum.repos.d/grafana.repo
Füge den folgenden Code in die Datei ein.
[grafana]
name=grafana
baseurl=https://packages.grafana.com/oss/rpm
repo_gpgcheck=1
enabled=1
gpgcheck=1
gpgkey=https://packages.grafana.com/gpg.key
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
Speichere die Datei, indem du Strg + X drückst und Y eingibst, wenn du dazu aufgefordert wirst.
Installiere Grafana.
$ sudo dnf install grafana
Starte und aktiviere den Grafana-Dienst.
$ sudo systemctl start grafana-server
$ sudo systemctl enable grafana-server
Schritt 7 – Grafana-Datenquelle einrichten
Starte die URL http://<serverIP>:3000 in deinem Browser und die folgende Anmeldeseite von Grafana sollte dich begrüßen.

Melde dich mit dem Standard-Benutzernamen admin und dem Passwort admin an. Als Nächstes musst du ein neues Standardpasswort einrichten.

Du wirst mit der folgenden Grafana-Startseite begrüßt. Klicke auf die Schaltfläche Füge deine erste Datenquelle hinzu.
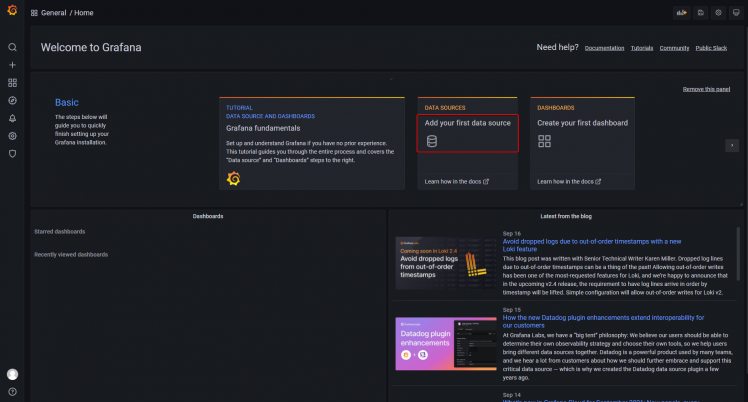
Klicke auf die Schaltfläche InfluxDB.
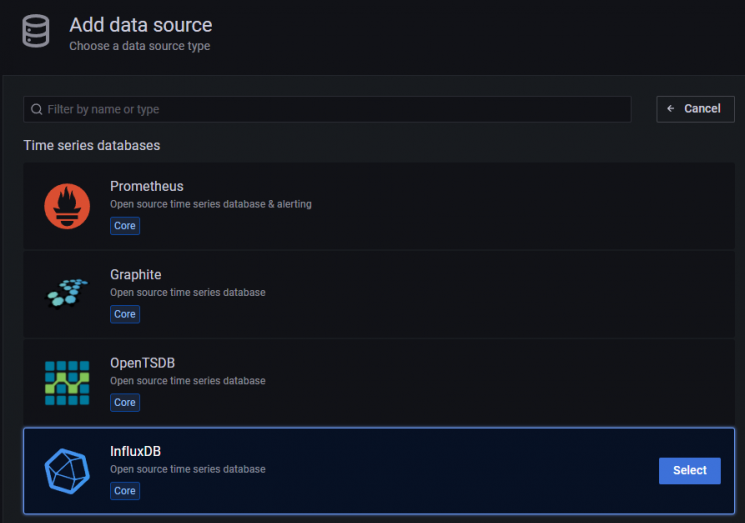
Auf der nächsten Seite wählst du Flux aus dem Dropdown-Menü als Abfragesprache aus. Du kannst auch InfluxQL als Abfragesprache verwenden, aber es ist komplizierter zu konfigurieren, da es standardmäßig nur InfluxDB v1.x unterstützt. Flux unterstützt InfluxDB v2.x und ist einfacher einzurichten und zu konfigurieren.

Gib die folgenden Werte ein.
URL: http://localhost:8086 Zugriff: Server Basic Auth Details Benutzer: navjot Passwort:
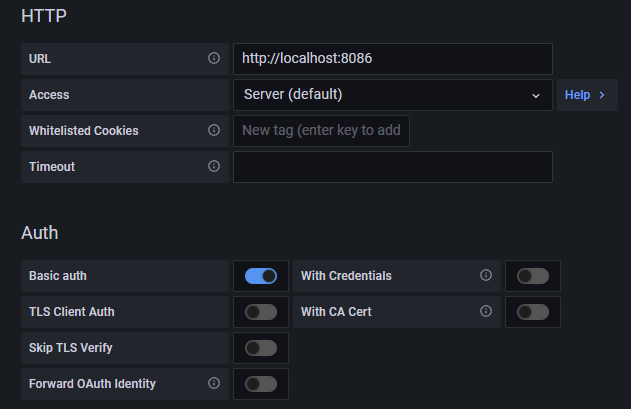
InfluxDB Details Organisation: howtoforge Token: Standard Bucket: tigstack

Klicke auf die Schaltfläche Speichern und testen und du solltest eine Bestätigungsmeldung sehen, die bestätigt, dass die Einrichtung erfolgreich war.

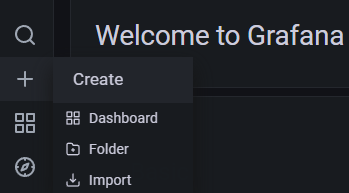
Schritt 8 – Grafana Dashboards einrichten
Im nächsten Schritt richtest du Grafana Dashboards ein. Klicke auf das + Zeichen und wähle Dashboards aus, um den Bildschirm Dashboard erstellen zu öffnen.
Auf der nächsten Seite klickst du auf die Schaltfläche Ein leeres Panel hinzufügen, um den folgenden Bildschirm zu öffnen.
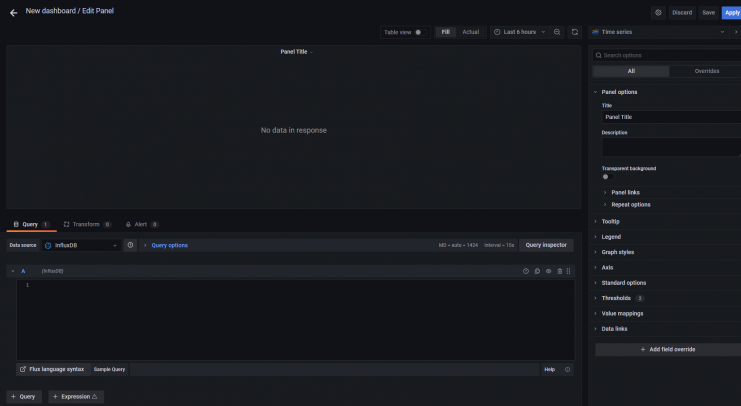
Füge den folgenden Code in den Abfrage-Editor ein. Diese
from(bucket: "NAMEOFYOUBUCKET")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "cpu")
|> filter(fn: (r) => r["_field"] == "usage_idle")
|> filter(fn: (r) => r["cpu"] == "cpu-total")
|> filter(fn: (r) => r["host"] == "NAMEOFYOURHOST")
|> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
|> map(fn: (r) => ({ r with _value: r._value * -1.0 + 100.0 }))
|> toFloat()
|> yield(name: "mean")
Verwende den Bucket-Namen, den wir oben verwendet haben. Und den Namen des Hosts, den du aus der Datei /etc/hostname abrufen kannst.
Der obige Code berechnet die CPU-Auslastung und erstellt ein Diagramm dazu. Gib dem Panel einen Titel. Klicke auf die Schaltfläche Abfrageinspektor, um zu überprüfen, ob deine Abfrage erfolgreich funktioniert. Wenn du mit dem Ergebnis zufrieden bist, klicke auf die Schaltfläche Anwenden, um fortzufahren.
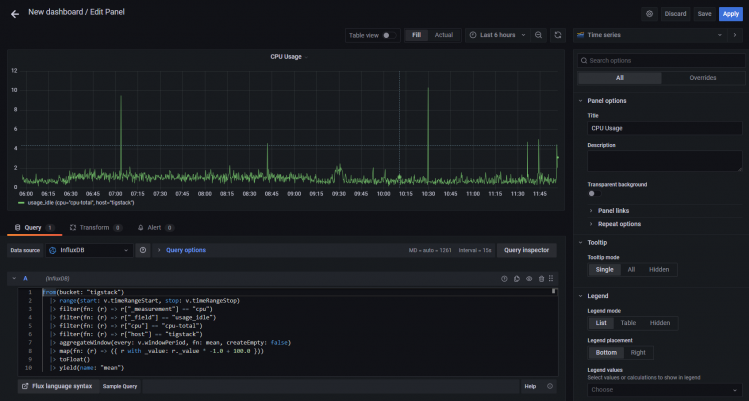
Du kannst der Achse auch einen Namen geben, indem du das Beschriftungsfeld rechts unter dem Achsenabschnitt benutzt.
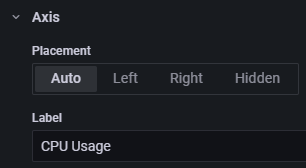
Klicke auf die Schaltfläche Übernehmen, um das Panel zu speichern.
Klicke auf die Schaltfläche Dashboard speichern, wenn du fertig bist.
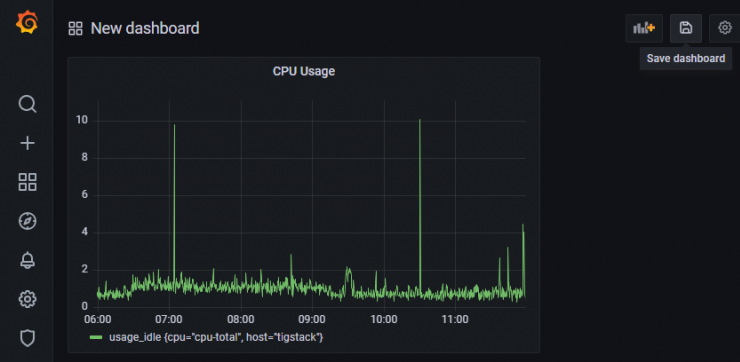
Gib dem Dashboard einen Namen und klicke zum Abschluss auf Speichern.

Das Dashboard wird geöffnet und du kannst auf die Schaltfläche Panel hinzufügen klicken, um ein weiteres Panel zu erstellen.

Wiederhole den Vorgang und erstelle ein weiteres Panel für die RAM-Auslastung.
from(bucket: "NAMEOFYOUBUCKET")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "mem")
|> filter(fn: (r) => r["_field"] == "used_percent")
|> filter(fn: (r) => r["host"] == "NAMEOFYOURHOST")
|> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
|> yield(name: "mean")
Und verwende den folgenden Code für die Anzeige der Festplattennutzung.
from(bucket: "NAMEOFYOURBUCKET")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "disk")
|> filter(fn: (r) => r["_field"] == "used")
|> filter(fn: (r) => r["path"] == "/")
|> filter(fn: (r) => r["host"] == "NAMEOFYOURHOST")
|> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
|> map(fn: (r) => ({ r with _value: r._value / 1000000.0 }))
|> toFloat()
|> yield(name: "mean")
Du kannst eine unbegrenzte Anzahl von Panels erstellen.
Der obige Code basiert auf der Flux Scripting Sprache. Zum Glück musst du diese Sprache nicht lernen, um Abfragen zu schreiben. Du kannst die Abfrage aus der InfluxDB URL generieren. Auch wenn das Erlernen der Sprache bei der Optimierung der Abfragen von Vorteil sein kann.
Um die Abfrage zu erhalten, musst du zum InfluxDB Dashboard zurückkehren und die Seite Explore öffnen.
Klicke auf den Bucket-Namen und dann auf einen der Werte im Filter _measurement und klicke immer wieder auf andere Werte, wenn sie erscheinen. Wenn du fertig bist, klicke auf die Schaltfläche Skript-Editor und du solltest die folgende Seite sehen. Das Diagramm sollte ebenfalls aktualisiert werden.
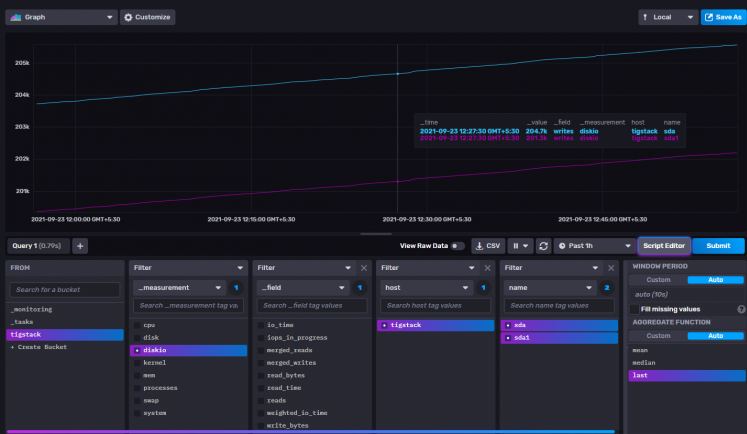
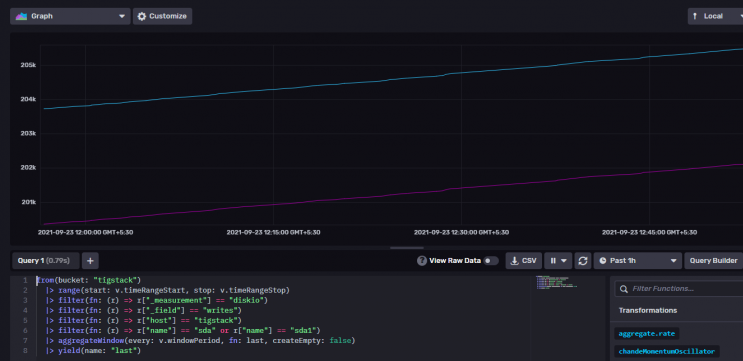
Kopiere die angezeigte Abfrage und du kannst sie jetzt im Grafana-Dashboard verwenden, um deine Diagramme zu erstellen.
Schritt 9 – Alarme und Benachrichtigungen konfigurieren
Die Einrichtung von Monitoren dient in erster Linie dazu, rechtzeitig Warnungen zu erhalten, wenn der Wert einen bestimmten Schwellenwert überschreitet.
Der erste Schritt besteht darin, das Ziel festzulegen, an das du die Benachrichtigungen senden möchtest. Du kannst Benachrichtigungen über E-Mail, Slack, Kafka, Google Hangouts Chat, Microsoft Teams, Telegram usw. erhalten.
Für unseren Lehrgang werden wir E-Mail-Benachrichtigungen aktivieren. Um E-Mail-Benachrichtigungen einzurichten, müssen wir zunächst den SMTP-Dienst konfigurieren. Öffne die Datei /etc/grafana/grafana.ini, um SMTP zu konfigurieren.
$ sudo nano /etc/grafana/grafana.ini
Suche darin die folgende Zeile [smtp]. Hebe die Kommentare in den folgenden Zeilen auf und gib die Werte für den benutzerdefinierten SMTP-Server ein.
[smtp]
enabled = true
host = email-smtp.us-west-2.amazonaws.com:587
user = YOURUSERNAME
# If the password contains # or ; you have to wrap it with triple quotes. Ex """#password;"""
password = YOURUSERPASSWORD
;cert_file =
;key_file =
;skip_verify = false
from_address = user@example.com
from_name = HowtoForge Grafana
# EHLO identity in SMTP dialog (defaults to instance_name)
;ehlo_identity = dashboard.example.com
# SMTP startTLS policy (defaults to 'OpportunisticStartTLS')
;startTLS_policy = NoStartTLS
Speichere die Datei, indem du Strg + X drückst und Y eingibst, wenn du dazu aufgefordert wirst.
Starte den Grafana-Server neu, um die Einstellungen zu übernehmen.
$ sudo systemctl restart grafana-server
Öffne die Grafana-Seite und klicke auf das Alert-Symbol und dann auf Benachrichtigungskanäle.
Klicke auf die Schaltfläche Kanal hinzufügen.
Gib die Details ein, um den E-Mail-Benachrichtigungskanal einzurichten.

Klicke auf Testen, um zu sehen, ob die E-Mail-Einstellungen funktionieren. Klicke auf Speichern, wenn du fertig bist.
Jetzt, wo wir die Benachrichtigungskanäle eingerichtet haben, müssen wir Benachrichtigungen einrichten, wenn wir diese E-Mails erhalten. Um die Benachrichtigungen einzurichten, musst du zurück zu den Dashboard-Panels gehen.
Klicke auf Dashboard >> Verwalten, um die Dashboard-Seite zu öffnen.

Klicke auf das Dashboard, das wir gerade erstellt haben, und du erhältst die Startseite mit den verschiedenen Bereichen. Um ein Panel zu bearbeiten, klicke auf den Namen des Panels und ein Dropdown-Menü öffnet sich. Klicke auf den Link Bearbeiten, um fortzufahren.
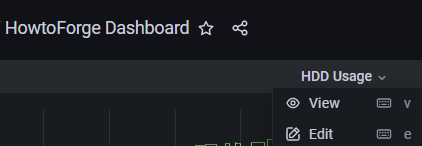
Klicke auf das Alarm-Panel und klicke auf die Schaltfläche Alarm erstellen, um einen neuen Alarm einzurichten.

Du kannst nun die Bedingungen konfigurieren, unter denen Grafana den Alarm sendet.
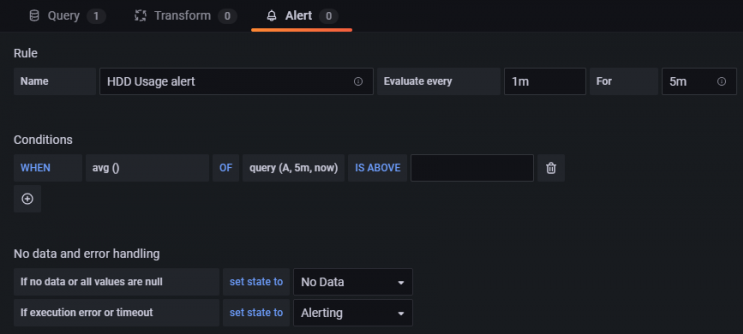
Regel
- Name – Gib einen beschreibenden Namen für den Alarm ein
- Auswerten alle – Lege fest, wie oft Grafana den Alert auswerten soll. Dies wird auch als Bewertungsintervall bezeichnet. Du kannst hier einen beliebigen Wert festlegen.
- Für – Lege fest, wie lange die Abfrage den Schwellenwert verletzen muss, bevor der Alarm ausgelöst wird. Ändere die Zeit nach deinen Bedürfnissen.
Bedingungen
Grafana arbeitet mit einer Abfrage des folgenden Formats, um zu bestimmen, wann ein Alert ausgelöst wird.
avg() OF query(A, 15m, now) IS BELOW 14
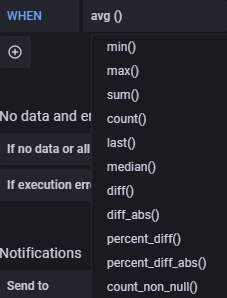
- avg() steuert, wie der Wert für jede Reihe auf einen vergleichbaren Wert zum Schwellenwert reduziert werden soll. Du kannst auf den Funktionsnamen klicken, um eine andere Funktion auszuwählen, z.B. avg(), min(), max(), sum(), count(), etc.

- Abfrage(A, 15m, jetzt) Der Buchstabe in der Klammer legt fest, welche Abfrage auf der Registerkarte Metriken ausgeführt werden soll. Die nächsten beiden Parameter legen den Zeitbereich fest. 15m, jetzt bedeutet von vor 15 Minuten bis jetzt.
- IS BELOW 14 Legt die Art des Schwellenwerts und den Schwellenwert fest. Du kannst auf IS BELOW klicken, um einen anderen Schwellentyp auszuwählen.
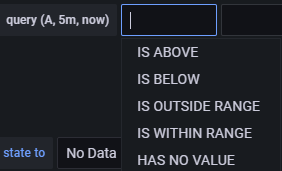
Du kannst eine zweite Bedingung darunter einfügen, indem du auf die Schaltfläche + unter der ersten Bedingung klickst. Derzeit kannst du nur die Operatoren AND und OR zwischen mehreren Bedingungen verwenden.
Keine Daten & Fehlerbehandlung
Du kannst konfigurieren, wie Grafana Abfragen behandeln soll, die keine Daten oder nur Nullwerte zurückgeben, indem du die folgenden Bedingungen verwendest:
- Keine Daten – Setze den Status der Regel auf
NoData - Alerting – Setzt den Regelstatus auf
Alerting - Keep Last State – Behält den aktuellen Status der Regel bei, egal wie er lautet
- Ok – Setze den Status der Alarmregel auf Ok, d.h. du bekommst einen Alarm, auch wenn alles in Ordnung ist.
Du kannst Grafana mitteilen, wie es mit Ausführungs- oder Timeout-Fehlern umgehen soll.
- Alerting – Setze den Status der Regel auf
Alerting - Letzten Zustand beibehalten – Behalte den aktuellen Zustand der Regel bei, egal wie er ist.
Benachrichtigungen
Du kannst Benachrichtigungen über die Regel zusammen mit einer detaillierten Nachricht über die Regel festlegen. Du kannst alle Informationen, die du im Zusammenhang mit der Warnung angeben möchtest, in deine Nachricht aufnehmen.
- Senden an – Wähle den Benachrichtigungskanal aus, an den wir die Warnmeldungen senden wollen.
- Nachricht – Gib eine Textnachricht ein, die zusammen mit deiner Warnung gesendet werden soll.
- Tags – Gib eine Liste von Tags (Schlüssel/Wert) an, die in der Benachrichtigung enthalten sein sollen. Sie werden nicht von allen Benachrichtigungskanälen (einschließlich E-Mail) unterstützt, daher kannst du sie leer lassen. Sie werden in der Regel verwendet, um Variablen und ihre Werte in der E-Mail zu versenden.
Wenn du fertig bist, klicke auf die Schaltfläche Regel testen, um zu sehen, ob alles gut funktioniert. Klicke auf die Schaltfläche Anwenden oben rechts, um das Hinzufügen der Warnmeldung abzuschließen.
Du solltest jetzt Benachrichtigungen in deiner E-Mail erhalten.
Fazit
Damit ist die Anleitung zur Installation und Konfiguration des TIG Stack auf einem Rocky Linux 8 basierten Server abgeschlossen. Wenn du noch Fragen hast, schreibe sie in die Kommentare unten.