So installierst du Apache Spark unter Ubuntu 22.04
Apache Spark ist eine kostenlose, quelloffene und universell einsetzbare Datenverarbeitungs-Engine, die von Datenwissenschaftlern verwendet wird, um extrem schnelle Datenabfragen auf großen Datenmengen durchzuführen. Sie nutzt einen In-Memory-Datenspeicher, um Abfragen und Daten direkt im Hauptspeicher der Clusterknoten zu speichern. Es bietet High-Level-APIs in den Sprachen Java, Scala, Python und R. Außerdem unterstützt es eine Vielzahl von Tools auf höherer Ebene wie Spark SQL, MLlib, GraphX und Spark Streaming.
In diesem Beitrag erfährst du, wie du die Datenverarbeitungs-Engine Apache Spark auf Ubuntu 22.04 installierst.
Voraussetzungen
- Ein Server, auf dem Ubuntu 22.04 läuft.
- Ein Root-Passwort ist auf dem Server eingerichtet.
Java installieren
Apache Spark basiert auf Java. Daher muss Java auf deinem Server installiert sein. Wenn es nicht installiert ist, kannst du es mit dem folgenden Befehl installieren:
apt-get install default-jdk curl -y
Sobald Java installiert ist, überprüfe die Java-Installation mit folgendem Befehl:
java -version
Du erhältst die folgende Ausgabe:
openjdk version "11.0.15" 2022-04-19 OpenJDK Runtime Environment (build 11.0.15+10-Ubuntu-0ubuntu0.22.04.1) OpenJDK 64-Bit Server VM (build 11.0.15+10-Ubuntu-0ubuntu0.22.04.1, mixed mode, sharing)
Apache Spark installieren
Zum Zeitpunkt der Erstellung dieses Tutorials ist die neueste Version von Apache Spark Spark 3.2.1. Du kannst sie mit dem Befehl wget herunterladen:
wget https://dlcdn.apache.org/spark/spark-3.2.1/spark-3.2.1-bin-hadoop3.2.tgz
Sobald der Download abgeschlossen ist, extrahiere die heruntergeladene Datei mit dem folgenden Befehl:
tar xvf spark-3.2.1-bin-hadoop3.2.tgz
Als Nächstes entpackst du die heruntergeladene Datei in das Verzeichnis /opt:
mv spark-3.2.1-bin-hadoop3.2/ /opt/spark
Als Nächstes bearbeitest du die Datei .bashrc und definierst den Pfad des Apache Spark:
nano ~/.bashrc
Füge die folgenden Zeilen am Ende der Datei hinzu:
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Speichere und schließe die Datei und aktiviere dann die Umgebungsvariable Spark mit dem folgenden Befehl:
source ~/.bashrc
Als Nächstes erstellst du einen eigenen Benutzer, um Apache Spark auszuführen:
useradd spark
Ändere als Nächstes den Eigentümer von /opt/spark auf den Benutzer spark und die Gruppe spark:
chown -R spark:spark /opt/spark
Erstellen einer Systemd-Dienstdatei für Apache Spark
Als Nächstes musst du eine Servicedatei erstellen, um den Apache Spark-Dienst zu verwalten.
Erstelle zunächst mit dem folgenden Befehl eine Servicedatei für den Spark-Master:
nano /etc/systemd/system/spark-master.service
Füge die folgenden Zeilen hinzu:
[Unit] Description=Apache Spark Master After=network.target [Service] Type=forking User=spark Group=spark ExecStart=/opt/spark/sbin/start-master.sh ExecStop=/opt/spark/sbin/stop-master.sh [Install] WantedBy=multi-user.target
Speichere und schließe die Datei und erstelle dann eine Servicedatei für Spark-Slave:
nano /etc/systemd/system/spark-slave.service
Füge die folgenden Zeilen hinzu:
[Unit] Description=Apache Spark Slave After=network.target [Service] Type=forking User=spark Group=spark ExecStart=/opt/spark/sbin/start-slave.sh spark://your-server-ip:7077 ExecStop=/opt/spark/sbin/stop-slave.sh [Install] WantedBy=multi-user.target
Speichere und schließe die Datei und lade den systemd-Daemon neu, um die Änderungen zu übernehmen:
systemctl daemon-reload
Starte und aktiviere als Nächstes den Spark-Master-Dienst mit dem folgenden Befehl:
systemctl start spark-master systemctl enable spark-master
Du kannst den Status des Spark-Masters mit folgendem Befehl überprüfen:
systemctl status spark-master
Du erhältst die folgende Ausgabe:
? spark-master.service - Apache Spark Master
Loaded: loaded (/etc/systemd/system/spark-master.service; disabled; vendor preset: enabled)
Active: active (running) since Thu 2022-05-05 11:48:15 UTC; 2s ago
Process: 19924 ExecStart=/opt/spark/sbin/start-master.sh (code=exited, status=0/SUCCESS)
Main PID: 19934 (java)
Tasks: 32 (limit: 4630)
Memory: 162.8M
CPU: 6.264s
CGroup: /system.slice/spark-master.service
??19934 /usr/lib/jvm/java-11-openjdk-amd64/bin/java -cp "/opt/spark/conf/:/opt/spark/jars/*" -Xmx1g org.apache.spark.deploy.mast>
May 05 11:48:12 ubuntu2204 systemd[1]: Starting Apache Spark Master...
May 05 11:48:12 ubuntu2204 start-master.sh[19929]: starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-spark-org>
May 05 11:48:15 ubuntu2204 systemd[1]: Started Apache Spark Master.
Sobald du fertig bist, kannst du mit dem nächsten Schritt fortfahren.
Zugriff auf Apache Spark
Zu diesem Zeitpunkt ist Apache Spark gestartet und lauscht auf Port 8080. Du kannst dies mit dem folgenden Befehl überprüfen:
ss -antpl | grep java
Du erhältst die folgende Ausgabe:
LISTEN 0 4096 [::ffff:69.28.88.159]:7077 *:* users:(("java",pid=19934,fd=256))
LISTEN 0 1 *:8080 *:* users:(("java",pid=19934,fd=258))
Öffne nun deinen Webbrowser und rufe die Spark-Weboberfläche über die URL http://your-server-ip:8080 auf. Auf der folgenden Seite solltest du das Dashboard von Apache Spark sehen:
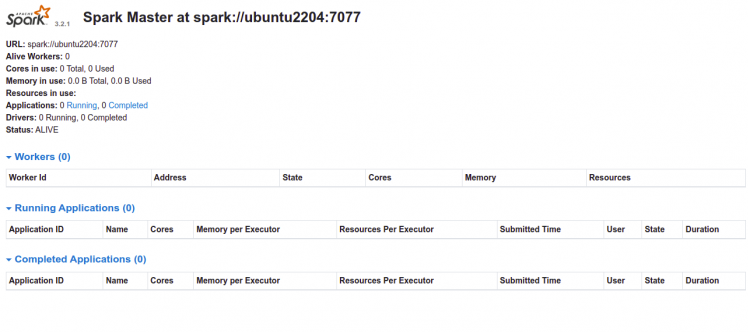
Starte nun den Spark-Slave-Dienst und aktiviere ihn so, dass er beim Neustart des Systems gestartet wird:
systemctl start spark-slave systemctl enable spark-slave
Du kannst den Status des Spark-Slave-Dienstes mit dem folgenden Befehl überprüfen:
systemctl status spark-slave
Du erhältst die folgende Ausgabe:
? spark-slave.service - Apache Spark Slave
Loaded: loaded (/etc/systemd/system/spark-slave.service; disabled; vendor preset: enabled)
Active: active (running) since Thu 2022-05-05 11:49:32 UTC; 4s ago
Process: 20006 ExecStart=/opt/spark/sbin/start-slave.sh spark://69.28.88.159:7077 (code=exited, status=0/SUCCESS)
Main PID: 20017 (java)
Tasks: 35 (limit: 4630)
Memory: 185.9M
CPU: 7.513s
CGroup: /system.slice/spark-slave.service
??20017 /usr/lib/jvm/java-11-openjdk-amd64/bin/java -cp "/opt/spark/conf/:/opt/spark/jars/*" -Xmx1g org.apache.spark.deploy.work>
May 05 11:49:29 ubuntu2204 systemd[1]: Starting Apache Spark Slave...
May 05 11:49:29 ubuntu2204 start-slave.sh[20006]: This script is deprecated, use start-worker.sh
May 05 11:49:29 ubuntu2204 start-slave.sh[20012]: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-spark-org.>
May 05 11:49:32 ubuntu2204 systemd[1]: Started Apache Spark Slave.
Gehe nun zurück zur Spark-Weboberfläche und aktualisiere die Webseite. Auf der folgenden Seite solltest du den hinzugefügten Worker sehen:
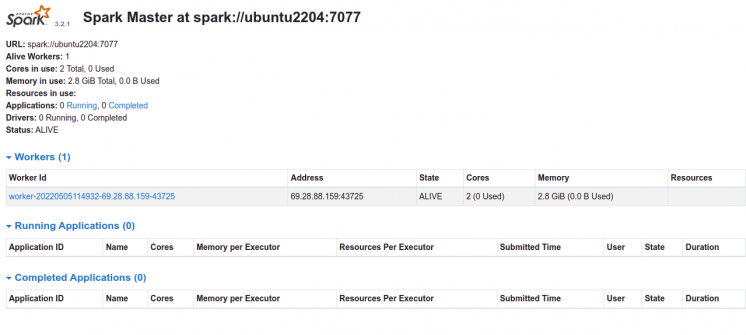
Klicke jetzt auf den Worker. Auf der folgenden Seite solltest du die Worker-Informationen sehen:
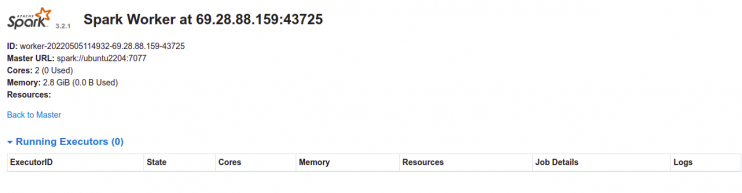
Zugriff auf die Spark-Shell
Apache Spark bietet auch ein Spark-Shell-Dienstprogramm, mit dem du über die Kommandozeile auf Spark zugreifen kannst. Du kannst es mit dem folgenden Befehl aufrufen:
spark-shell
Du erhältst die folgende Ausgabe:
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/jars/spark-unsafe_2.12-3.2.1.jar) to constructor java.nio.DirectByteBuffer(long,int)
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
22/05/05 11:50:46 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://ubuntu2204:4040
Spark context available as 'sc' (master = local[*], app id = local-1651751448361).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.2.1
/_/
Using Scala version 2.12.15 (OpenJDK 64-Bit Server VM, Java 11.0.15)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
Um die Spark-Shell zu verlassen, führe den folgenden Befehl aus:
scala> :quit
Wenn du ein Python-Entwickler bist, kannst du mit pyspark auf Spark zugreifen:
pyspark
Du erhältst die folgende Ausgabe:
Python 3.10.4 (main, Apr 2 2022, 09:04:19) [GCC 11.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/jars/spark-unsafe_2.12-3.2.1.jar) to constructor java.nio.DirectByteBuffer(long,int)
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
22/05/05 11:53:17 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.2.1
/_/
Using Python version 3.10.4 (main, Apr 2 2022 09:04:19)
Spark context Web UI available at http://ubuntu2204:4040
Spark context available as 'sc' (master = local[*], app id = local-1651751598729).
SparkSession available as 'spark'.
>>>
Drücke die Tastenkombination STRG + D, um die Spark-Shell zu verlassen.
Fazit
Glückwunsch! Du hast Apache Spark erfolgreich auf Ubuntu 22.04 installiert. Jetzt kannst du Apache Spark in der Hadoop-Umgebung verwenden. Weitere Informationen findest du auf der Apache Spark-Dokumentationsseite.